
-
- 1.1. 概念
- 1.2. Eureka 客户端与服务器之间的通信
- 1.3. Eureka自我保护模式
- 1.3.1. 关闭自我保护
- 1.4. 使用Eureka的步骤
- 1.4.1. 搭建eureka服务端。
- 1.4.2. 使用eureka客户端
- 1.4.3. 使用eureka集群
-
- 2.1. RestTemplate使用ribbon
- 2.2. 轮询算法原理
-
- 3.1. 步骤
-
- 4.1. 使用步骤
- 4.2. Eureka、Zookeeper、Consul三个注册中心的异同点
- 4.2.1. CAP理论
-
- 5.1. 使用步骤
-
- 6.1. 简介
- 6.2. 作用
- 6.3. 服务降级
- 6.3.1. 使用步骤
- 6.4. 服务熔断
- 6.4.1. 使用服务熔断
- 6.5. hystrix准监控调用
- 6.5.1. 使用步骤
- 6.6. 使用feign整合hystrix
- 6.6.1. 步骤
-
- 9.1. 概述
- 9.2. 组成和常用的注解
- 9.3. Binder Implementations 绑定器
- 9.4. 工作模式
- 9.5. 使用步骤(使用rabbit)
- 9.6. 重复消费问题
- 9.6.1. 解决方法
- 9.7. 消息持久化问题
springcloud
springcloud和alibaba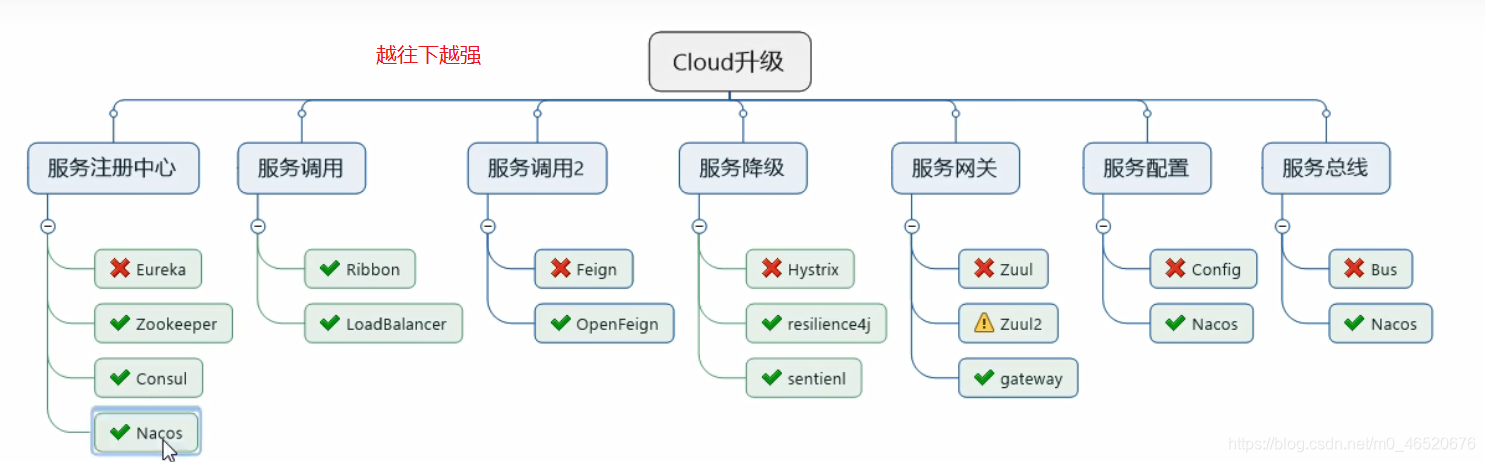
SpringCloud 是微服务一站式服务解决方案,微服务全家桶。它是微服务开发的主流技术栈。它采用了名称,而非数字版本号。
springCloud 和 springCloud Alibaba 目前是最主流的微服务框架组合。
根pom文件的依赖
1 | <properties> |
1. 服务注册之Eureka
官方停更
1.1. 概念
它是用来服务治理,以及服务注册和发现。
Eureka包含两个组件:Eureka Server和Eureka Client
- Eureka Server提供服务注册中心,各个微服务节点通过配置启动后,会在EurekaServer中进行注册,这样EurekaServer中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观看到
- Eureka Client通过注册中心进行访问。一个Java客户端,用于简化与 Eureka Server 的交互(通常就是微服务中的客户端和服务端)
1.2. Eureka 客户端与服务器之间的通信
- Register(注册)
Eureka客户端将关于运行实例的信息注册到Eureka服务器。注册发生在第一次心跳。
- Renew(更新 / 续借)
Eureka客户端需要更新最新注册信息(续借),通过每30秒发送一次心跳。更新通知是为了告诉Eureka服务器实例仍然存活。如果服务器在90秒内没有看到更新,它会将实例从注册表中删除。建议不要更改更新间隔,因为服务器使用该信息来确定客户机与服务器之间的通信是否存在广泛传播的问题。
- Fetch Registry(抓取注册信息)
Eureka客户端从服务器获取注册表信息并在本地缓存。之后,客户端使用这些信息来查找其他服务。通过在上一个获取周期和当前获取周期之间获取增量更新,这些信息会定期更新(每30秒更新一次)。获取的时候可能返回相同的实例。Eureka客户端自动处理重复信息。
- Cancel(取消)
Eureka客户端在关机时向Eureka服务器发送一个取消请求。这将从服务器的实例注册表中删除实例,从而有效地将实例从流量中取出。
1.3. Eureka自我保护模式
如果 Eureka 服务器检测到超过预期数量的注册客户端以一种不优雅的方式终止了连接,并且同时正在等待被驱逐,那么它们将进入自我保护模式。这样做是为了确保灾难性网络事件不会擦除eureka注册表数据,并将其向下传播到所有客户端。
任何客户端,如果连续3次心跳更新失败,那么它将被视为非正常终止,病句将被剔除。当超过当前注册实例15%的客户端都处于这种状态,那么自我保护将被开启。
当自我保护开启以后,eureka服务器将停止剔除所有实例,直到:
它看到的心跳续借的数量回到了预期的阈值之上,或者
自我保护被禁用
默认情况下,自我保护是启用的,并且,默认的阈值是要大于当前注册数量的15%
1.3.1. 关闭自我保护
注册中心配置:
1 | server: |
服务端配置:
1 | lease-renewal-interval-in-seconds: 1 # eureka客户端向服务端发送心跳的时间间隔 单位秒 默认30 |
1.4. 使用Eureka的步骤
要先搭建服务端,客户端再进行注册。且必须要加入actuator的pom,eureka才能够监听
1.4.1. 搭建eureka服务端。
- 加入eureka服务端的pom(此处版本号在根项目中给出)
1 | <!--eureka-server--> |
- 配置文件
1 | eureka: |
- 在启动类中加入注解@EnableEurekaServer,开启eureka服务
Eureka界面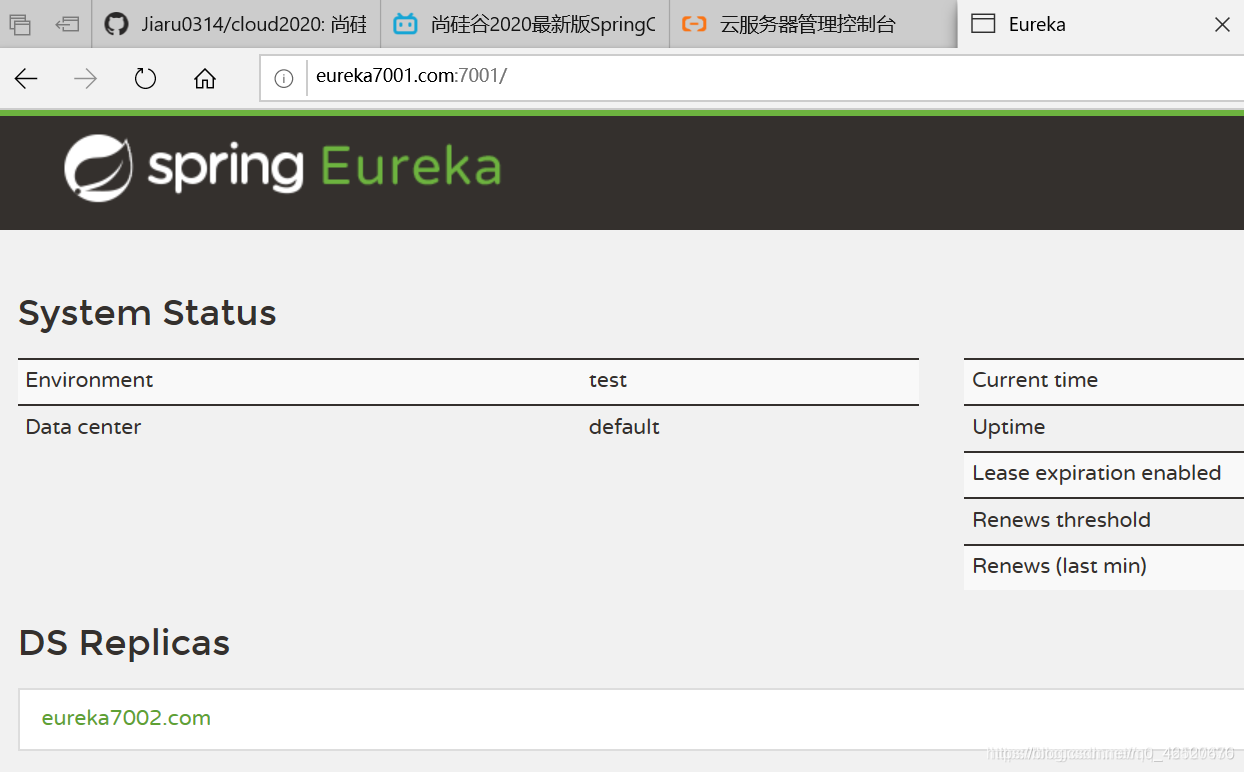
1.4.2. 使用eureka客户端
- 加入客户端pom
1 | <!--eureka-client--> |
- 配置文件,与服务端的区别为是否向注册中心注册自己
1 | eureka: |
- 在启动类中加入注解
1 | //eureka客户端 |
1.4.3. 使用eureka集群
注册中心修改配置,多个eureka服务端相互注册,互相守望
1 | eureka: |
客户端修改配置,注册地址为eureka集群
1 | eureka: |
2. 使用Ribbon实现负载均衡
若eureka中的生产者有多个,为生产者集群,而在消费者在eureka中是使用服务名来进行消费,而生产者集群中的服务名都相同,则消费者不能确定是哪一个服务。此时要使用Ribbon来实现负载均衡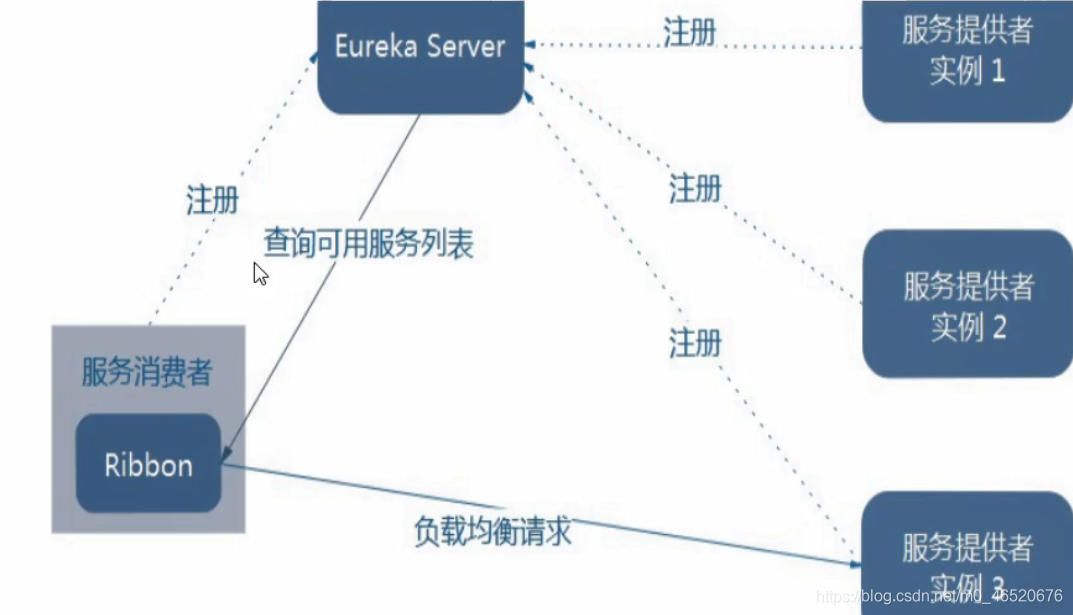
如下图所示,服务名cloud-payment-service下有两个微服务8001和8002,而消费者cloud-order-service使用服务名cloud-payment-service来进行消费。
要配置生产者集群,只需在application.yml文件中配置name相同即可
1 | spring: |
2.1. RestTemplate使用ribbon
如果要使用RestTemplate来使用Ribbon,需要在配置RestTemplate的地方加入注解@LoadBalanced
1 |
|
此时消费者可以通过http://CLOUD-PAYMENT-SERVICE/ 来访问,默认是轮询方式,访问模式为8001,8002,8001…….
2.2. 轮询算法原理
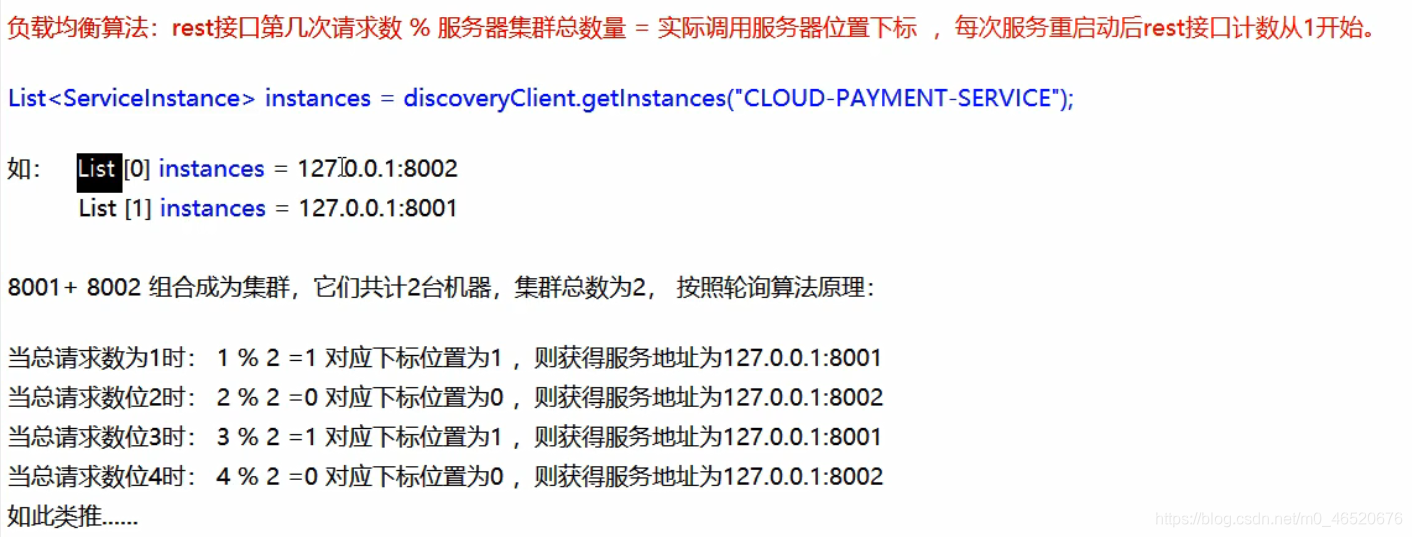
2.2.1. 实现轮询算法
ribbon轮询算法实现了IRule接口
1 | public interface IRule{ |
轮询算法类RoundRobinRule,轮询算法的关键实现为choose方法
1 | public class RoundRobinRule extends AbstractLoadBalancerRule { |
仿照choose方法,自己实现一个轮询算法:
1.创建接口LoadBalancer
1 | public interface LoadBalancer { |
- 实现接口,写轮询算法
1 |
|
- 关闭@LoadBalanced注解,模拟负载均衡
1 |
|
2.2.2. 替换负载规则
- 添加规则类
注意: 官方文档明确给出了警告:
这个自定义配置类不能放在 @ComponentScan 所扫描的当前包下以及子包下,否则自定义的配置类就会被所有的 Ribbon 客户端所共享,达不到特殊化定制的目的了。
1 |
|
- 主启动类添加 @RibbonClient
1 |
|
- 此时替换为了随机算法
3. 使用zookeeper注册中心
与eureka类似,只需改注解为@EnableDiscoveryClient和在配置文件中注册进zookeeper即可
3.1. 步骤
- 在docker中启动zookeeper
1 | # docker run --name zk01 -p 2180:2180 --restart always -d 7341c5373a13 |
- 加入zookeeper和其和springboot整合的pom
1 | <!--SpringBoot整合Zookeeper客户端--> |
- 修改配置文件,注册进zookeeper,生产者和消费者是一样的
1 | spring: |
- 主启动类加入注解@EnableDiscoveryClient,然后就可以和eureka一样的访问zookeeper了,可以通过服务名访问
4. 使用consul注册中心
使用consul步骤与eureka类似,只不过是将@EnableEurekaClient改为了@EnableDiscoveryClient并注册为consul
4.1. 使用步骤
- 在docker中启动consul
1 | docker run -d --name consul -p 8500:8500 consul |
- 加入consul的pom文件
1 | <!--springcloud consul server--> |
- 修改配置文件,注册至consul,生产者和消费者是一样的
1 | spring: |
- 主启动类加入注解@EnableDiscoveryClient,然后就可以和eureka一样的访问consul了
- consul的控制台在8500端口
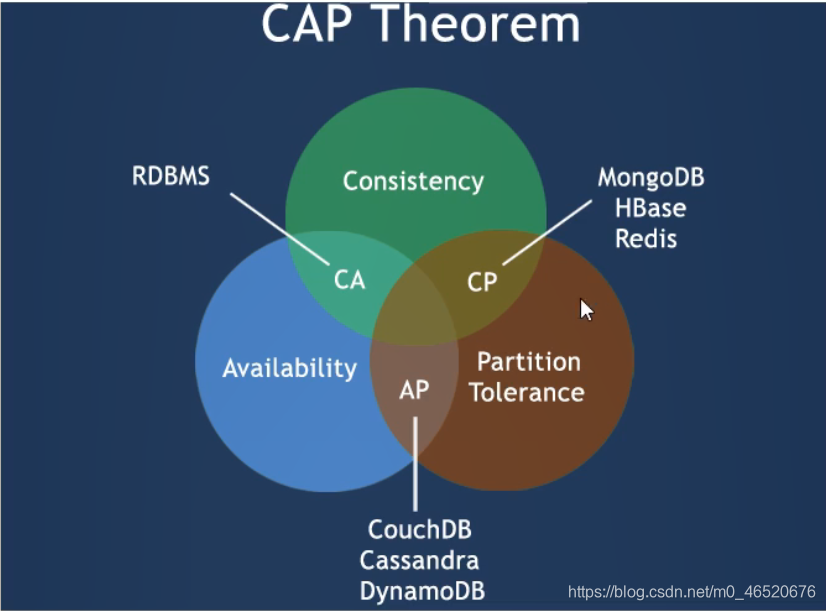
4.2. Eureka、Zookeeper、Consul三个注册中心的异同点

4.2.1. CAP理论

5. 使用feign进行远程调用
feign是声明式的web service客户端,它让微服务之间的调用变得更简单了,类似controller调用service。Spring Cloud集成了Ribbon和Eureka,可在使用Feign时提供负载均衡的http客户端。

feign的pom文件中有ribbon的依赖,因此也可以改变负载规则。
5.1. 使用步骤
- 引入feign
1 | <!--openfeign--> |
- 配置feign
1 | # 设置feign客户端超时时间(OpenFeign默认支持ribbon) |
- 加入注解@EnableFeignClients,开启feign
1 |
|
- 面向接口编程,创建一个feign接口,方法签名与想调用的服务的方法签名一致。然后在接口上加入 @FeignClient注解,将接口注入调用。
1 | //该注解使用feign实现服务间的互相调用,只需要一个接口即可 |
远程调用的方法,签名一致
1 |
|
- 调用接口方法,feign会远程调用eureka中对应的服务的对应的方法(签名相同)
1 |
|
注意:使用feign调用post请求时,使用@RequstParam注解时,远程时会接受不到参数,需要使用@RequstBody注解才可以,参数直接传给feign接口即可。
6. Hystrix
已停止更新
6.1. 简介
在微服务场景中,通常会有很多层的服务调用。如果一个底层服务出现问题,故障会被向上传播给用户。我们需要一种机制,当底层服务不可用时,可以阻断故障的传播。这就是断路器的作用。他是系统服务稳定性的最后一重保障。
在springcloud中断路器组件就是Hystrix。Hystrix也是Netflix套件的一部分。他的功能是,当对某个服务的调用在一定的时间内(默认10s),有超过一定次数(默认20次)并且失败率超过一定值(默认50%),该服务的断路器会打开。返回一个由开发者设定的fallback。
fallback可以是另一个由Hystrix保护的服务调用,也可以是固定的值。fallback也可以设计成链式调用,先执行某些逻辑,再返回fallback。

6.2. 作用
对通过第三方客户端库访问的依赖项(通常是通过网络)的延迟和故障进行保护和控制。
在复杂的分布式系统中阻止级联故障。
快速失败,快速恢复。
回退,尽可能优雅地降级。
启用近实时监控、警报和操作控制。
6.3. 服务降级
服务器忙碌或者网络拥堵时,不让客户端等待并立刻返回一个友好提示,fallback
服务降级类似于if else语句,如果if语句出问题,需要有else来处理。如果微服务出问题,需要有fallback方法处理。
服务降级的情况:
- 访问超时
- 运行错误
- 宕机
- 服务熔断导致服务降级
6.3.1. 使用步骤
- 引入hystrix
1 | <dependency> |
- 主启动类注解@EnableCircuitBreaker
1 |
|
- 写业务方法和兜底方法,在业务方法上加上注解@HystrixCommand指明其兜底方法,fallback属性指明兜底方法
1 | /** |
问题
每个方法有一个对应的处理方法,代码膨胀。
处理方法和主业务逻辑混合在一起
解决方法
- 在业务类上加注解@DefaultProperties(defaultFallback=””),并指明默认兜底类
1 |
|
- 默认全局处理方法
1 |
|
- @HystrixCommand不加属性代表使用默认的全局处理方法。
6.4. 服务熔断
实际上服务熔断 和 服务降级 没有任何关系,就像 java 和 javaScript
服务熔断,有点自我恢复的味道


hystrix熔断的三种状态
6.4.1. 使用服务熔断
方法要使用熔断机制,需要在@HystrixCommand中配置4个参数:
- circuitBreaker.enabled。
是否开启断路器
- circuitBreaker.sleepWindowInMilliseconds。
断路器的快照时间窗,也叫做窗口期。可以理解为一个触发断路器的周期时间值,默认为10秒(10000)。
- circuitBreaker.requestVolumeThreshold。
断路器的窗口期内触发断路的请求阈值,默认为20。换句话说,假如某个窗口期内的请求总数都不到该配置值,那么断路器连发生的资格都没有。断路器在该窗口期内将不会被打开。
- circuitBreaker.errorThresholdPercentage。
断路器的窗口期内能够容忍的错误百分比阈值,默认为50(也就是说默认容忍50%的错误率)。打个比方,假如一个窗口期内,发生了100次服务请求,其中50次出现了错误。在这样的情况下,断路器将会被打开。在该窗口期结束之前,即使第51次请求没有发生异常,也将被执行fallback逻辑。
综上所述,在以上三个参数缺省的情况下,Hystrix断路器触发的默认策略为:
在10秒内,发生20次以上的请求时,假如错误率达到50%以上,则断路器将被打开。(当一个窗口期过去的时候,断路器将变成半开(HALF-OPEN)状态,如果这时候发生的请求正常,则关闭,否则又打开)
1 | //=====服务熔断 |
熔断后会进行服务降级,以后的访问都会调用paymentCircuitBreaker_fallback方法,而不是paymentCircuitBreaker方法。
6.5. hystrix准监控调用

6.5.1. 使用步骤
需要新建一个工程来使用dashboard
- 引入dashboard,该工程无需引入其他hystrix的pom,只用来提供监控页面,服务提供者前提要有actuator的依赖和web的依赖
1 | <!-- hystrix Dashboard,图形化界面--> |
- 在主启动类上加上注解@EnableHystrixDashboard
1 |
|
- 使用http://localhost:9001/hystrix访问监控页面,使用教程略

注意点: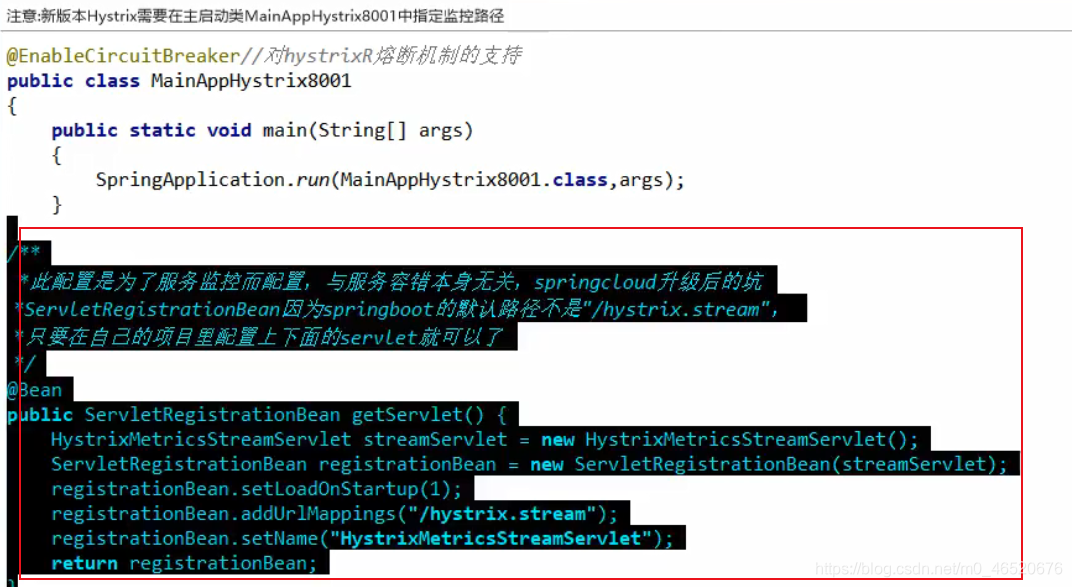
6.6. 使用feign整合hystrix
6.6.1. 步骤
- 引入hystrix和openfeign的pom
- 在启动类加注解@EnableHystrix,该为feign对hystrix的支持。加入@EnableFeignClients,开启feign
1 |
|
- yml配置开启feign对hystrix的支持
1 | feign: |
- 全局服务降级:实现feign调用方法的接口,并在接口的FeignClient注解中指明fallback类为其实现类。哪个接口方法发生错误就会调用实现类的对应方法兜底
feign接口
1 | /** |
实现类
1 | /** |
- 设置默认兜底方法@DefaultProperties(defaultFallback = “payment_Global_FallbackMethod”)
当方法发生异常且加有@HystrixCommand注解但未指定兜底方法时,会调用默认方法
注意:
- feign所调用的微服务发送错误才会使用实现类的兜底方法。
7. 服务网关
API网关是一个服务器,是系统的唯一入口。从面向对象设计的角度看,它与外观模式类似。API网关封装了系统内部架构,为每个客户端提供一个定制的API。它可能还具有其它职责,如身份验证、监控、负载均衡、缓存、请求分片与管理、静态响应处理。API网关方式的核心要点是,所有的客户端和消费端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。通常,网关也是提供REST/HTTP的访问API。
网关应当具备以下功能:
- 性能:API高可用,负载均衡,容错机制。
- 安全:权限身份认证、脱敏,流量清洗,后端签名(保证全链路可信调用),黑名单(非法调用的限制)。
- 日志:日志记录(spainid,traceid)一旦涉及分布式,全链路跟踪必不可少。
- 缓存:数据缓存。
- 监控:记录请求响应数据,api耗时分析,性能监控。
- 限流:流量控制,错峰流控,可以定义多种限流规则。
- 灰度:线上灰度部署,可以减小风险。
- 路由:动态路由规则。
图片来自废物大师兄的博客园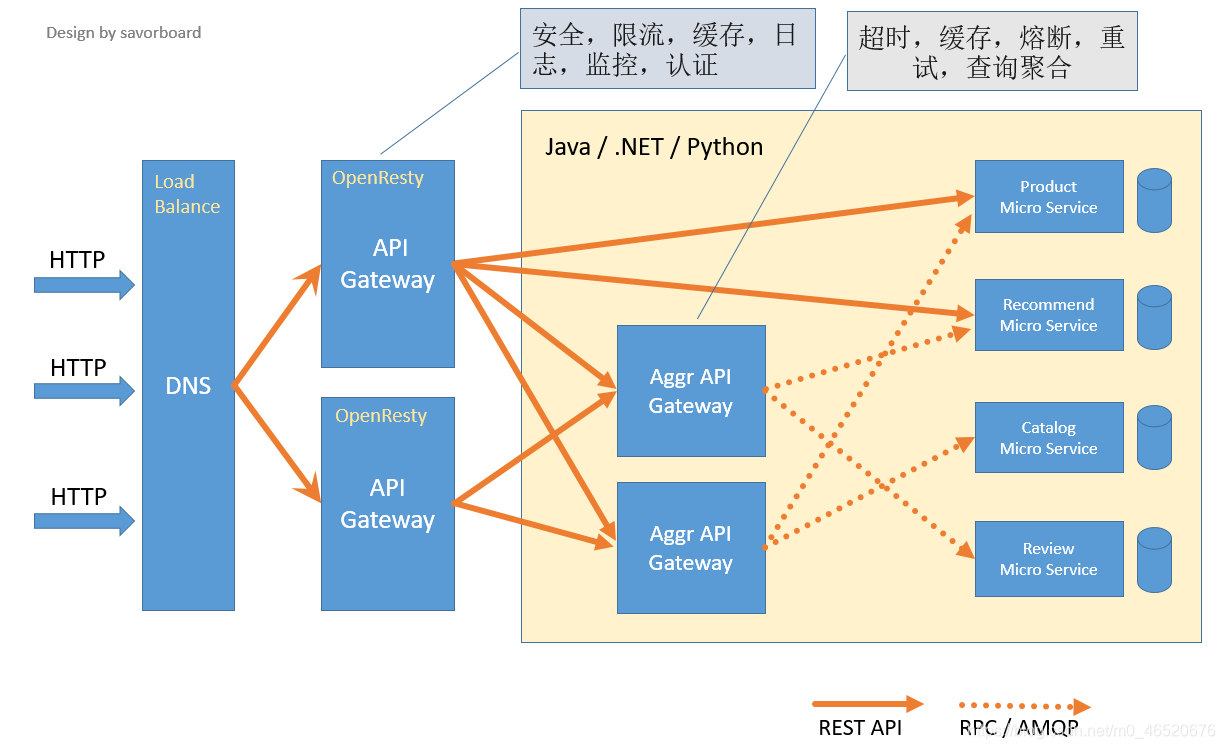
7.1. Gateway
Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。
Spring Cloud Gateway 作为 Spring Cloud 生态系统中的网关,目标是替代 Netflix Zuul,其不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,和限流。
7.1.1. 术语
Route : 路由是网关的基本组件。它由ID、目标URI、谓词集合和过滤器集合定义。如果聚合谓词为true,则匹配路由
Predicate : This is a Java 8 Function Predicate,如果请求和断言相匹配,则进行路由
Filter : 是GatewayFilter的一个实例,在这里,可以在发送下游请求之前或之后修改请求和响应
7.1.2. 工作流程
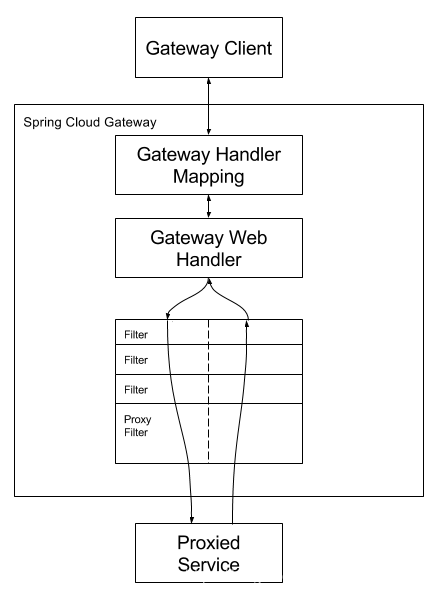
更形象的描述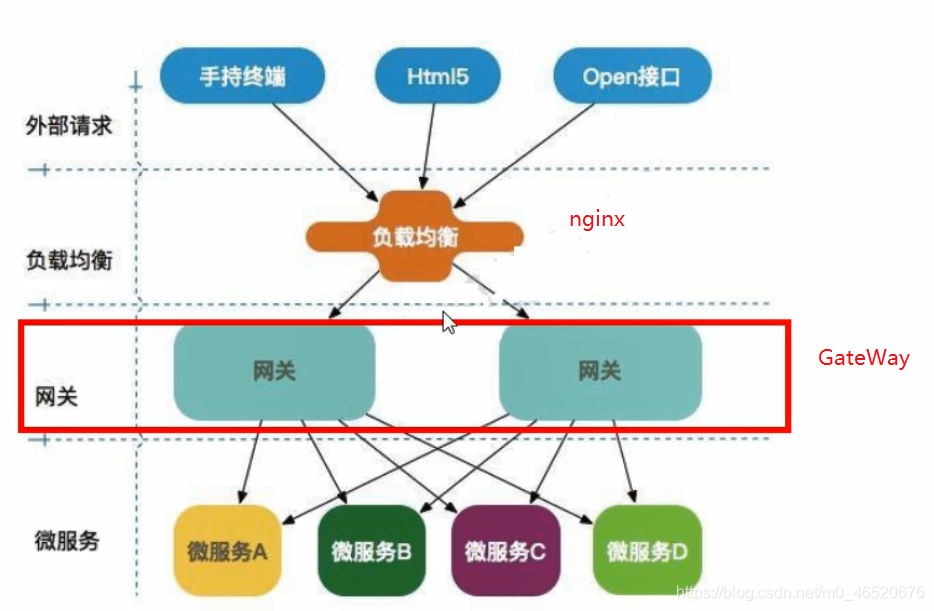
7.1.3. 使用步骤
- 引入gateway。web和gateway不能同时存在,需要移除web和acuator的依赖
1 | <!--gateway--> |
- yml配置,此处已配置好了断言,如果请求和断言相匹配,则进行路由。断言规则还有很多,例如根据时间进行断言等等,具体参考官网
1 | server: |
- 无需在启动类上加相应的注解,只要加入eureka或者其他注册中心的注解即可
- 此时可以使用http://CLOUD-PAYMENT-SERVICE/payment/1 来访问8001,效果和http://localhost:8001/payment/1 一样
使用网关来访问隐藏了真实的微服务地址,如果规则不匹配就会报错
注意:
- 使用微服务名来配置routes的uri时,要加上前缀lb
- 网关也是个微服务,也要进入注册中心,所以也要加入eureka的pom
其他断言规则: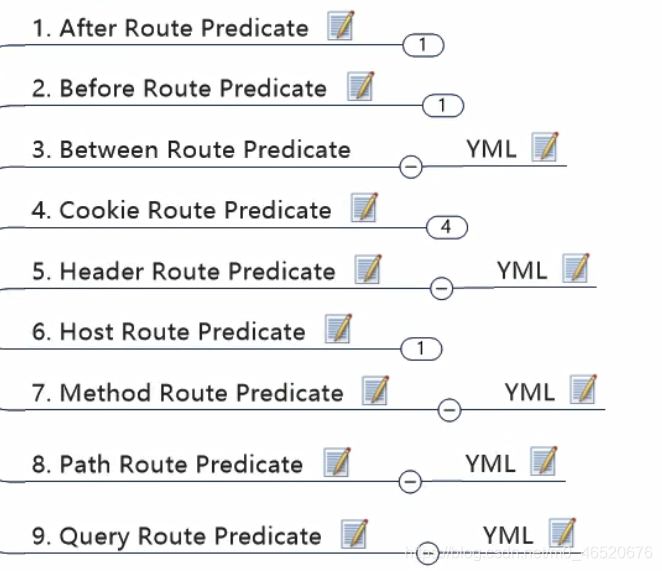
部分断言规则示例
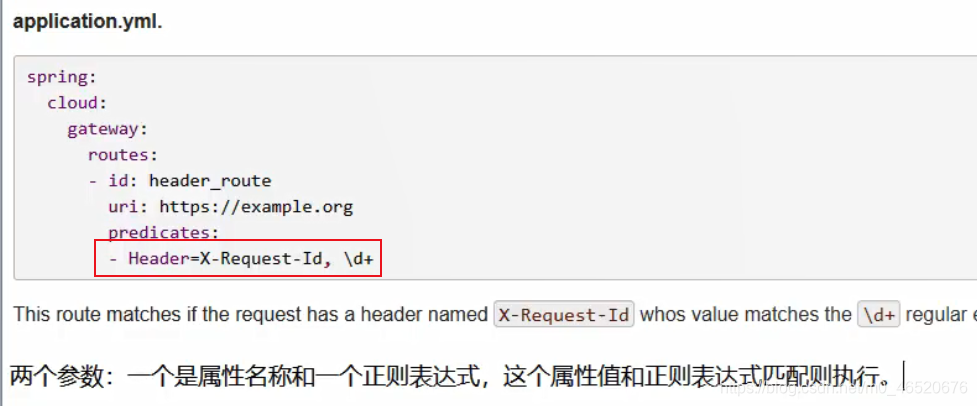
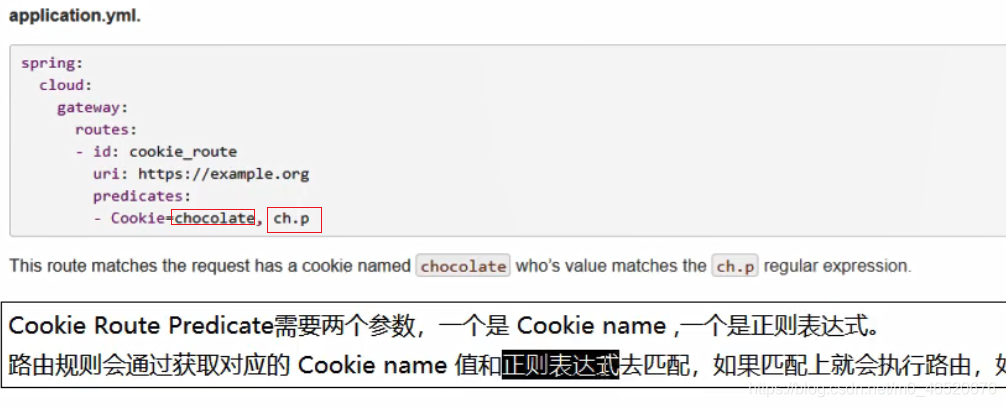
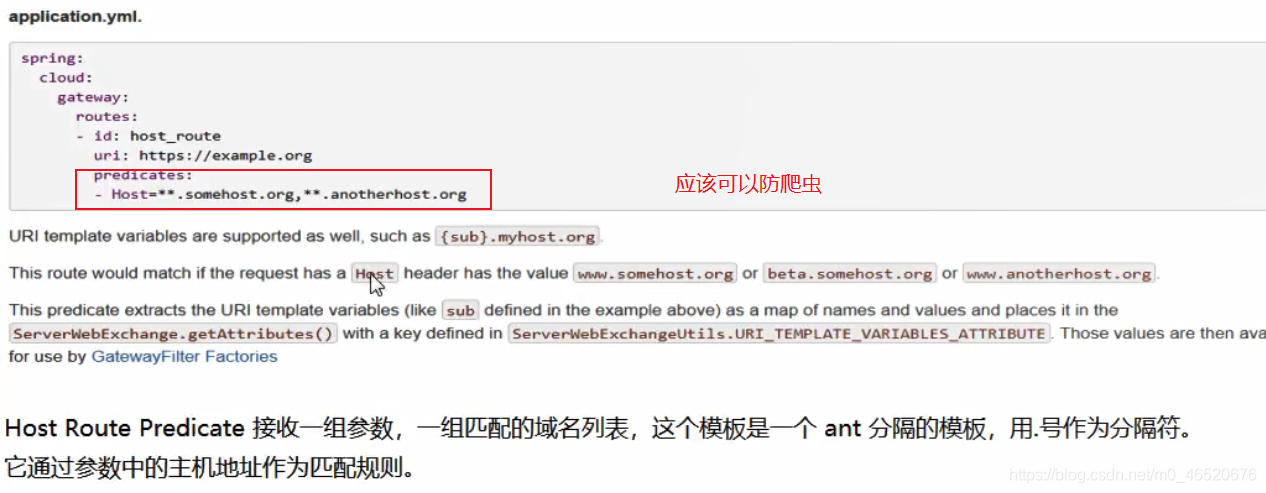
7.1.4. 设置全局过滤器
全局过滤器作用于所有的路由,不需要单独配置,我们可以用它来实现很多统一化处理的业务需求,比如权限认证,IP访问限制等等
步骤
- 创建一个类,实现接口Ordered, GlobalFilter
- 加@Component注解
- 在filter方法中写逻辑
下面的例子时校验用户名是否为null,如果为null,不进行路由,直接返回
1 | /** |
8. SpringCloud Config
SpringCloud Config 分布式配置中心
8.1. 简介
在分布式系统中,由于服务数量巨多,为了方便服务配置文件统一管理,实时更新,所以需要分布式配置中心组件。Spring Cloud Config项目是就是这样一个解决分布式系统的配置管理方案。它包含了Client和Server两个部分,server提供配置文件的存储、以接口的形式将配置文件的内容提供出去,client通过接口获取数据、并依据此数据初始化自己的应用。
8.2. 使用步骤
8.2.1. 配置中心
- 在github上新建一个仓库,然后新建开发、生产、测试配置文件,并提交到github
- 引入config依赖。
1 | <!--springcloud配置中心--> |
- 在配置文件中加入配置
1 | server: |
- 在主启动类上添加注解@EnableConfigServer
1 |
|
- Spring Cloud Config 有它的一套访问规则,我们通过这套规则在浏览器上直接访问就可以。
/{application}/{profile}[/{label}] /{application}-{profile}.yml
/{label}/{application}-{profile}.yml
/{application}-{profile}.properties
/{label}/{application}-{profile}.properties
任一即可
{application} 就是应用名称,对应到配置文件上来,就是配置文件的名称部分,例如我上面创建的配置文件。
{profile} 就是配置文件的版本,我们的项目有开发版本、测试环境版本、生产环境版本,对应到配置文件上来就是以 application-{profile}.yml 加以区分,例如application-dev.yml、application-sit.yml、application-prod.yml。
{label} 表示 git 分支,默认是 master 分支,如果项目是以分支做区分也是可以的,那就可以通过不同的 label 来控制访问不同的配置文件了。
1 | config: |
8.2.2. 客户端
新建一个客户端,来使用config注册中心的配置
- 引入config客户端pom,和注册中心不同
1 | <!-- config Client 和 服务端的依赖不一样 --> |
- 在bootstrap.yml配置文件(bootstrap.yml优先级高与application.yml)
bootstrap.yml和application.yml官方描述
Spring Cloud 构建于 Spring Boot 之上,在 Spring Boot 中有两种上下文,一种是 bootstrap,
另外一种是 application, bootstrap 是应用程序的父上下文,也就是说 bootstrap 加载优先于
applicaton。bootstrap
主要用于从额外的资源来加载配置信息,还可以在本地外部配置文件中解密属性。这两个上下文共用一个环境,它是任何Spring应用程序的外部属性的来源。bootstrap
里面的属性会优先加载,它们默认也不能被本地相同配置覆盖。

1 | spring: |
- 加入注解@RefreshScope来动态刷新配置,此时可以使用rest端口从配置中心获取配置
1 |
|
- 当更改github上的配置文件内容时,需要向每个客户端发送一次post请求来手动刷新配置(前提客户端暴露了监控端点,并且引入了actuator)
如 curl -X POST “http://localhost:3355/actuator/refresh"
两个必须:
1.必须是 POST 请求,
2.请求地址:http://localhost:3355/actuator/refresh
8.2.3. 问题
就是要向每个微服务发送一次POST请求,当微服务数量庞大,又是一个新的问题。此时可以使用消息总线来一次性刷新所有配置。
8.3. 消息总线
8.3.1. 概念

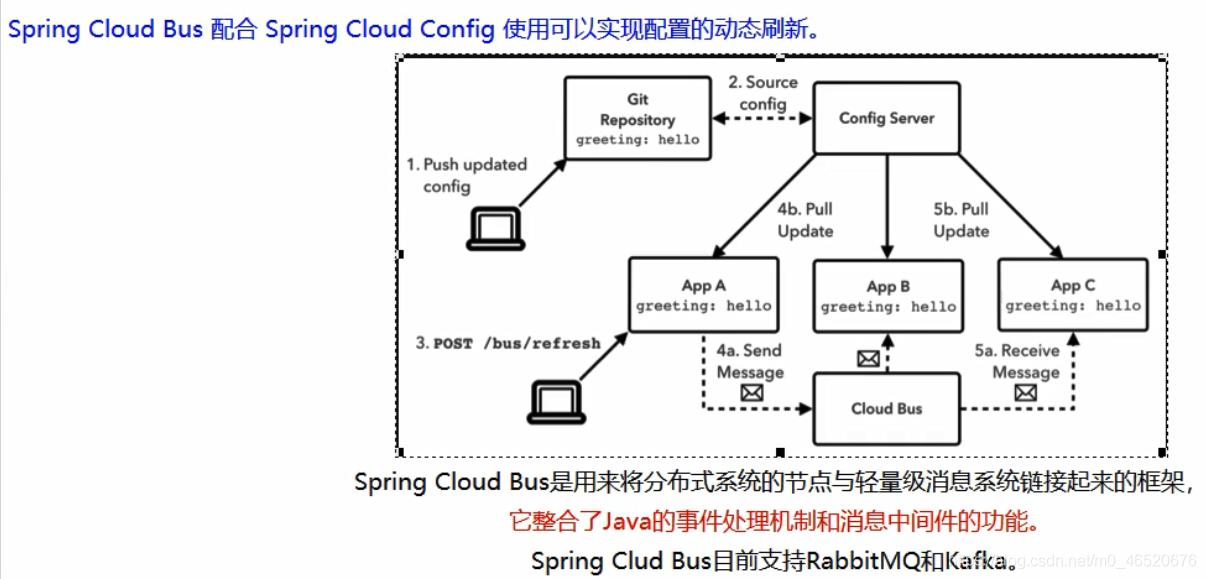
8.3.2. 使用消息总线(bus)服务端动态刷新至所有客户端
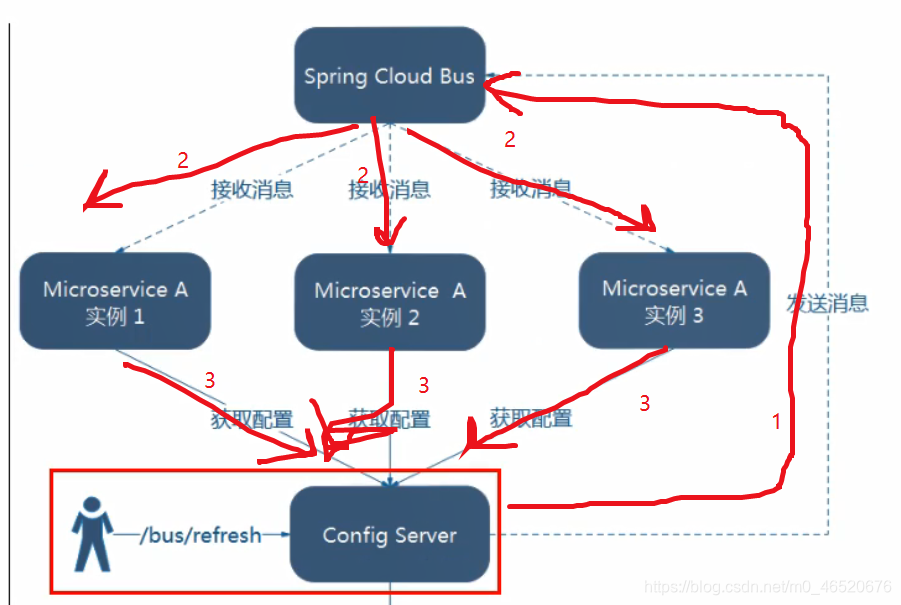
- 在docker中启动rabbitmq
1 | docker run -d -p 5672:5672 -p 15672:15672 --name rabbitmq rabbitmq:management |
- 在注册中心和客户端都添加上rabbitmqbus的依赖
1 | <!--添加消息总线rabbitmq的支持--> |
- 配置rabbitmq,默认用户名和密码都是guest,配置中心和客户端都有加上rabbitmq的配置
1 | # 配置中心,客户端类似,加上rabbit配置即可 |
- 配置配置中心暴露refresh端点,用于广播式通知,即只需要刷新配置中心就可以使所有客户端的配置得到更新
1 | # 暴露bus刷新配置的端点 |
- 更新配置后,发送post请求来刷新(此时只需对3344发送即可,只刷一台机器处处生效)
使用curl -X POST “http://localhost:3344/actuator/bus-refresh"
定点通知:如果只想通知一个,定点清除,则使用(只通知3355),/微服务:端口号
curl -X POST “http://localhost:3344/actuator/bus-refresh/config-client:3355"

9. 消息驱动Stream
9.1. 概述
Spring Cloud Stream 是一个用来为微服务应用构建消息驱动能力的框架。它可以基于 Spring Boot 来创建独立的、可用于生产的 Spring 应用程序。Spring Cloud Stream 为一些供应商的消息中间件产品提供了个性化的自动化配置实现,并引入了发布-订阅、消费组、分区这三个核心概念。通过使用 Spring Cloud Stream,可以有效简化开发人员对消息中间件的使用复杂度,让系统开发人员可以有更多的精力关注于核心业务逻辑的处理。但是目前 Spring Cloud Stream 只支持 RabbitMQ 和 Kafka 的自动化配置。
问题:为什么要引入SpringCloud Stream?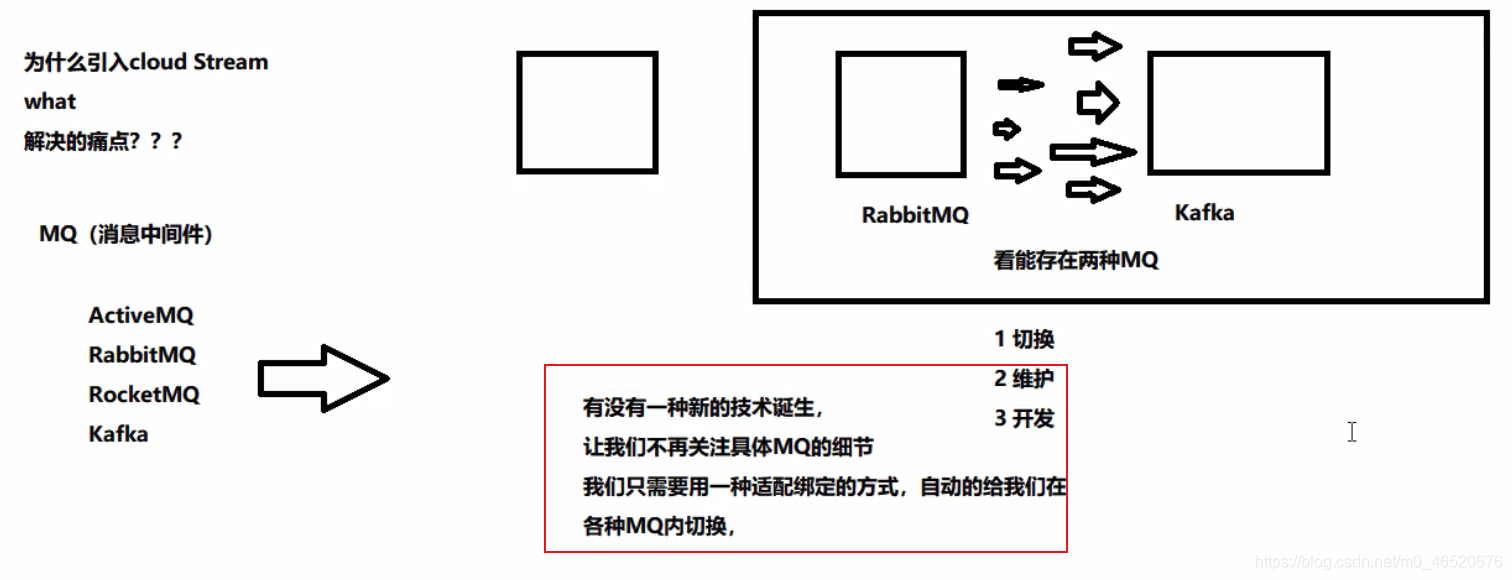
- 一句话:屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型
9.2. 组成和常用的注解

9.3. Binder Implementations 绑定器
通过绑定器Binder作为中间件,实现了应用程序与消息中间件细节的解耦。
Input对应消息生产者
Output对应消息消费者
9.4. 工作模式
就像 JDBC 形成一种规范,统一不同数据库的接口
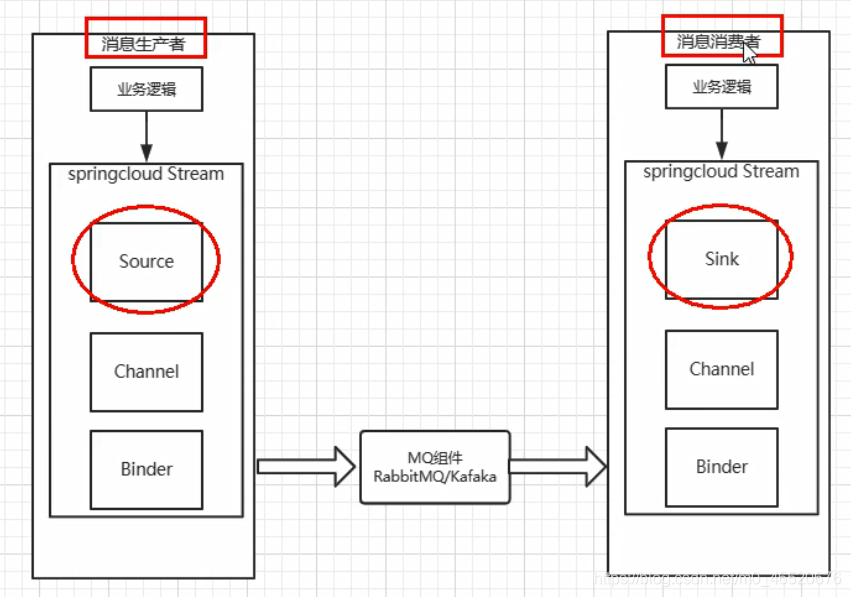
消息生产者绑定一个source,而消息消费者绑定一个sink
9.5. 使用步骤(使用rabbit)
- 加入stream对rabbit的支持
1 | <dependency> |
- 配置yml,要配置好注册中心和rabbit
1 | # 生产者8801 |
1 | # 消费者和生产者不同的地方 |
- 定义生产者发送消息的业务接口和其实现类,在上面加上注解@EnableBinding(Source.class)绑定一个source,使用消息发送管道MessageChannel来发送消息。在哪个类发送消息就在哪个类加上注解。controller层方法略
1 | /** |
- 定义消费者接受消息的类,在上面加上注解@EnableBinding(Sink.class)绑定一个sink。在监听方法上加上一个监听器的注解@StreamListener(Sink.INPUT),该方法会监听管道的消息。
1 | /** |
- 使用生产者的sendMessage方法发送消息,此时rabbitmq的界面和消费者的控制台都会接收到消息
9.6. 重复消费问题
此时有两个消费者8802和8803,会存在消息的重复消费问题,即两个消费者会收到同一个消息。rabbitmq会发向两个消费者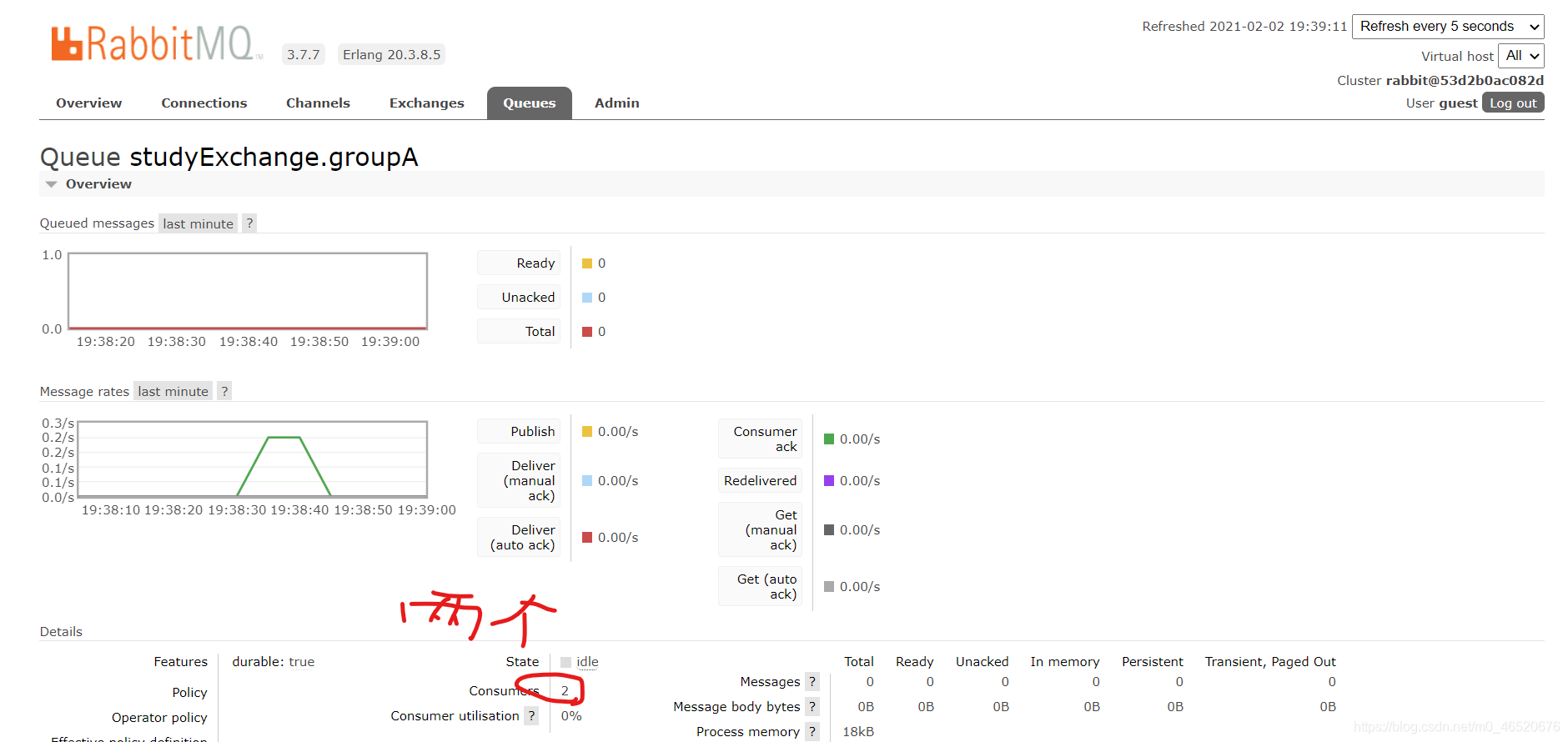
不同的组存在重复消费,相同的组之间竞争消费。
9.6.1. 解决方法
对消费者进行分组,将8802和8803分在同一组内,保证消息只会被其中一个应用消费一次
在消费者8802和8803的yml文件中加入分组配置
1 | # 8802 的消费者 |
此时8801发送消息,只有一个消费者接受到消息了
9.7. 消息持久化问题
当消费者微服务停止时生产者发的消息,会在消费者重启后接收到,是持久化的,前提是绑定的队列没变(group属性没变)
加上group配置,就已经实现了消息的持久化。
10. SpringCloud Sleuth和zipkin
分布式请求链路跟踪,超大型系统。需要在微服务模块极其多的情况下,比如80调用8001的,8001调用8002的,这样就形成了一个链路,如果链路中某环节出现了故障,我们可以使用Sleuth进行链路跟踪,从而找到出现故障的环节。
需要和zipkin一起使用
10.1. 工作原理
ParentId时其上一个服务的SpanId,由此就可以找到上一个服务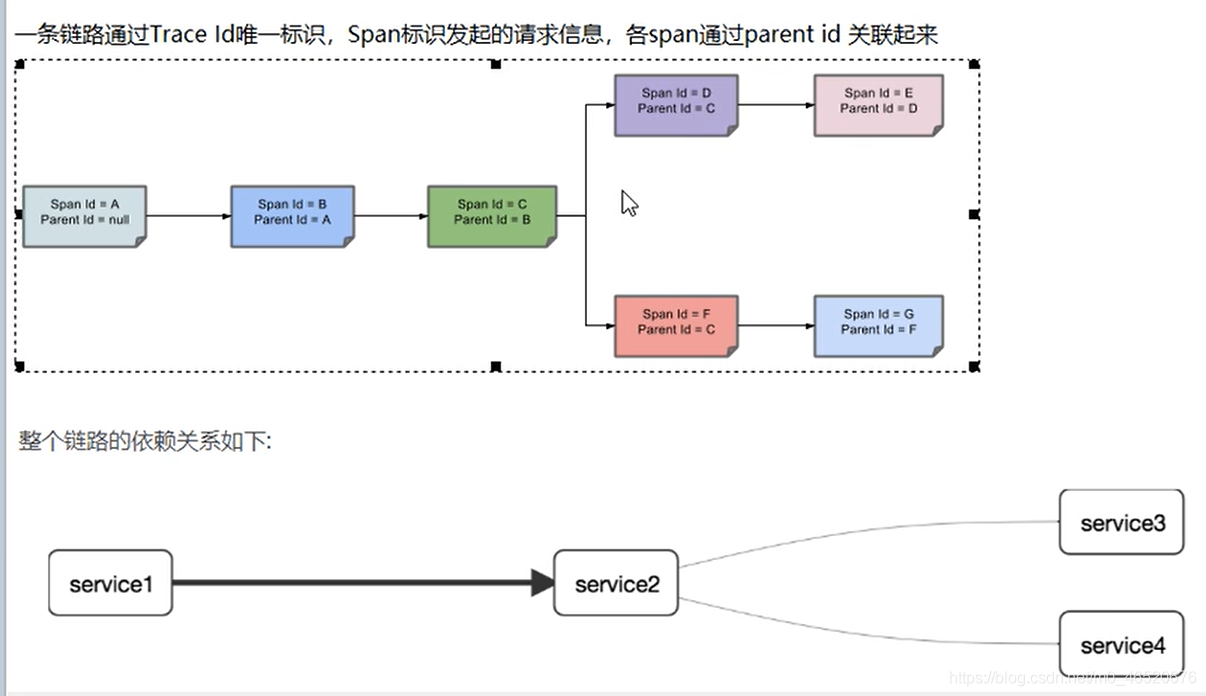
10.2. 使用步骤
- 运行zipkin的jar,可以使用
- 在消费者中配置
1 | spring: |
- 消费者微服务进行远程调用
- 访问localhost:9411/zipkin/ 来使用zipkin进行链路追踪

