机器学习入门
吴恩达机器学习笔记
什么是机器学习
- 陈旧的定义(Arthur Samuel):在没有明确设置的情况下使计算机具有学习能力的研究领域
- 新的定义(Tom Mitchell):”A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T,as measured by P, improves with experience E.”
简单的一句话:机器学习就是让机器从大量的数据集中学习,进而得到一个更加符合现实规律的模型,通过对模型的使用使得机器比以往表现的更好。
主要的学习算法
简单来说,监督学习就是我们会教计算机做某件事情,无监督学习就是让计算机自己学习。
监督学习
- 定义:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。
监督学习的分类:回归问题(Regression)、分类问题(Classification)
回归问题(Regression)
我们想要预测连续的数值输出,这就是回归问题。例如预测房价,假如你的朋友想卖掉他的房子,他想知道能卖多少钱。
此时可以使用回归算法来根据数据集来画一条直线或二次函数来拟合数据,如下图所示,直线拟合出来能卖150k,而曲线拟合出来是200k

要通过不断学习,找到最合适的模型得到拟合数据,在这里为房价。
**回归通俗一点就是,对已经存在的点(训练数据)进行分析,拟合出适当的函数模型y=f(x),这里y就是数据的标签,而对于一个新的自变量x,通过这个函数模型得到标签y。 **
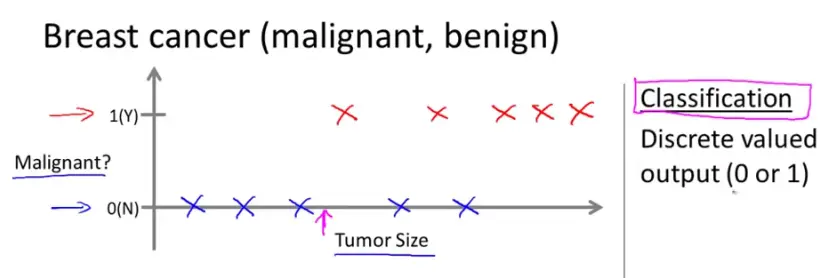
分类问题(Classification)
我们设法预测一个离散值输出,这就是分类问题。例如估计肿瘤性质,某人发现了一个乳腺癌,在乳腺上有个肿块,假设在数据集中,1是恶性的,0是良性的。此时分类算法就用来根据肿瘤大小来估计是恶性还是良性,输出结果只有‘是’和‘否’,是离散的。
在上面的例子中只使用了一个特征(feature)或者属性,即肿瘤的大小来预测。在其他机器学习问题中特征可能不只一个,如下图是根据年龄和肿瘤大小两个属性来预测
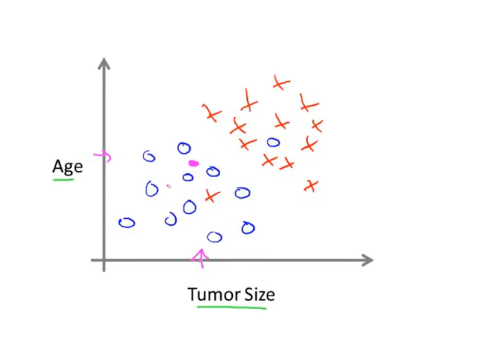
此时学习算法能做的就是在数据集上画出一条直线设法将恶性肿瘤和良性肿瘤分开,此时就可以通过这个来判断某人肿瘤的类型。
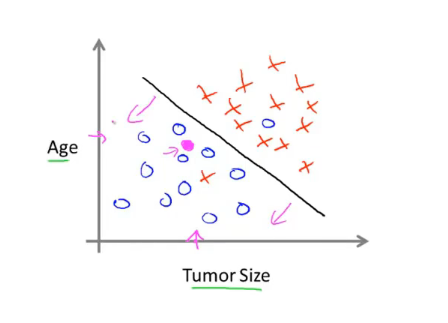
所以简单来说分类就是,要通过分析输入的特征向量,对于一个新的向量得到其标签。
无监督学习
- 定义:据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。
我们得到一个数据集,我们不知道拿他干什么,也不知道每个数据点究竟是什么,我们只被告知这里有一个数据集,无监督学习方法可以把这些数据分成两个不同的簇,这就是聚类算法。
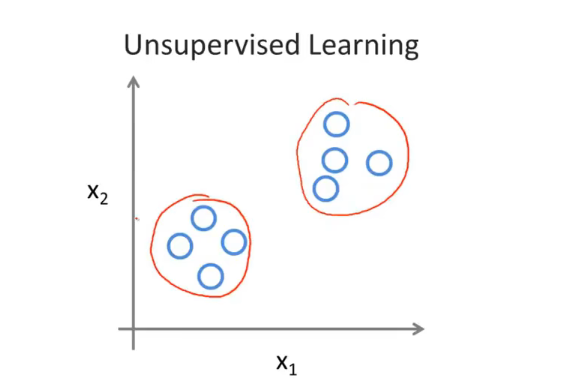
聚类算法(Clustering)
一个应用聚类算法的例子就是谷歌新闻,谷歌新闻所做的就是去搜索成千上万条新闻,然后自动地将他们分簇,有关同一主题的新闻被显示在一起,如下图所示
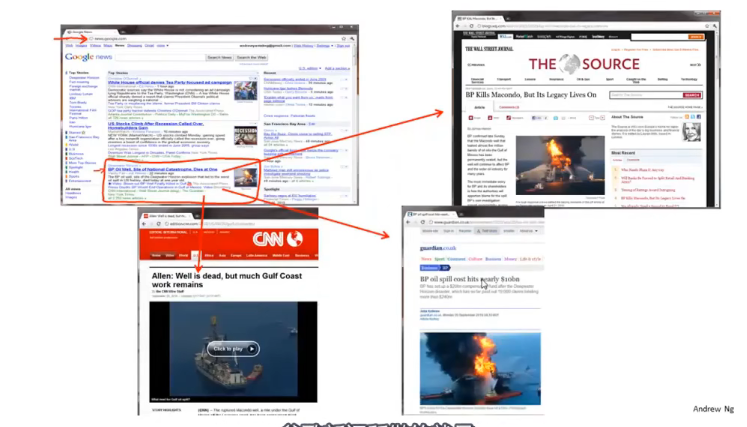
监督学习
线性回归
监督学习算法的工作方式:以预测房价为例,我们向学习算法提供训练集(房价训练集),学习算法的任务是输出一个函数h,h代表假设函数,其作用是把房子的大小作为输入变量,而它会试着输出相应房子的预测值。
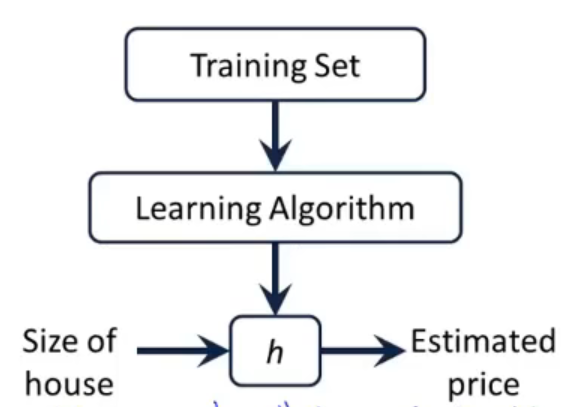
对于房价预测,选取初始假设函数为一个线性函数$h(x) = \theta_1x + \theta_0$,在拟合线性函数的基础上最终处理更加复杂的模型以及学习更复杂的学习算法,这个模型被成为线性回归。
这个例子是一个一元线性回归,是一个单变量的函数,θ称之为模型参数。我们所要做的就是如何选择这两个参数值$\theta_0$和$\theta_1$来让假设函数表示的直线尽量地与训练集中的数据点很好的拟合,使得在训练集中给出的x值能够合理准确地预测y的值。

代价函数
我们知道了现有的数据是准确的,那么预测就要以现有的数据为根基,尽量的贴合现有的数据,使得差距最小,因此使用代价函数来衡量这个差距。
我们使用平均平方和误差作为一元线性回归的代价函数,定义如下:
$$
J(\theta_0,\theta_1)=\frac{1}{2m}\displaystyle \sum^{m}_{i=1}{(h(x^i)-y^i)^2}
$$
m是训练集的样本数,h(x)是预测值,y为真实值
- 注:之所以是1/2m ,是因为带了平方,后面要用梯度下降法,要求导,这样求导多出的乘2就和二分之一抵消了,一个简化后面计算的技巧。
$$
minmize\theta_0,\theta_1( \frac{1}{2m}\displaystyle \sum^{m}_{i=1}{(h(x^i)-y^i)^2})
$$
这个表示关于$\theta_0$和$\theta_1$的最小化过程,这意味着我们要找到$\theta_0$和$\theta_1$的值来使这个表达式的值最小,因此这将是线性回归的整体目标函数。
简单的例子
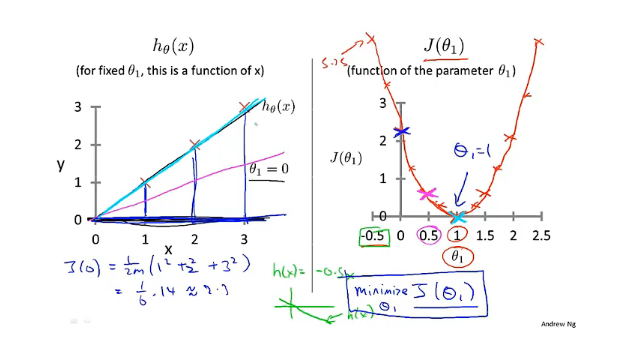
看下面一个例子,假设$h(x) = \theta_1x $ ,即$\theta_0=0$ 时的假设函数,通过调整$\theta_1$的值来看代价函数$j(\theta_1)$的变化。对于这个训练集,可以看见当$\theta_1=1$时拟合的最好(淡蓝色的线),此时代价函数的值最小(等于0)。这就是为什么要最小化$J(\theta_1)$,可以找到一条最符合数据的直线。
较复杂的例子
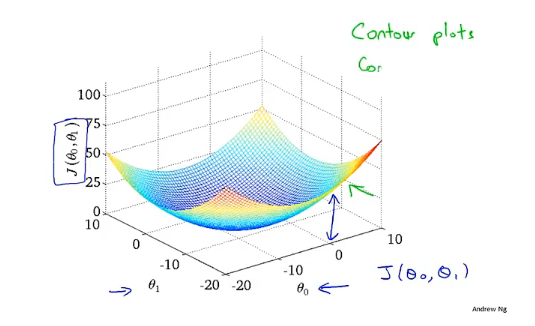
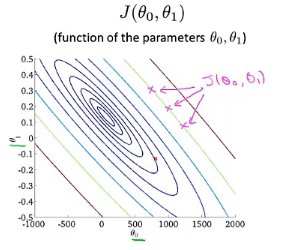
当代价函数为$J(\theta_0,\theta_1)$时,其图像为下面这个样子,是个三维图形,旁边是对应的等高线图,同一条线上的值相同,下面的例子将使用等高线图来代替三维图
当$\theta_0$取500,$\theta_1$取接近于0的一个数时,对应的线并不能很好的拟合数据,此时代价函数的值并不小
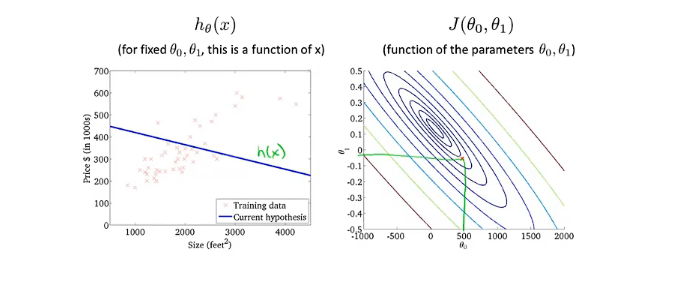
再将$\theta_0$和$\theta_1$取另外两个数,这时直线能够很好的拟合数据,代价函数也非常小,接近于0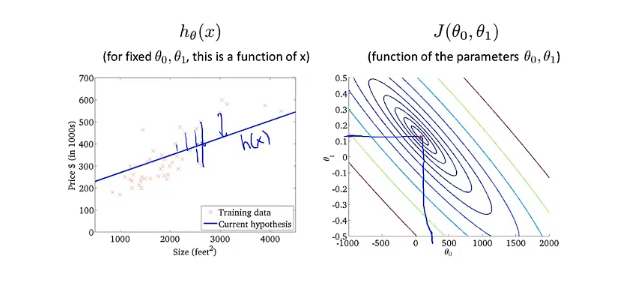
通过这两个例子可以更好的理解代价函数的意义,如何对应不同的假设函数以及接近代价函数J最小值的点对应着更好的假设函数。
梯度下降算法
假设代价函数为$J(\theta_0,\theta_1)$,目标是最小化此代价函数,可使用梯度下降算法
步骤:
- 给定$\theta_0和\theta_1$的初始值(通常都设为0)
- 不停地一点点改变$\theta_0和\theta_1$来使$J(\theta_0,\theta_1)$变小,直到我们找到最小值或局部最小值
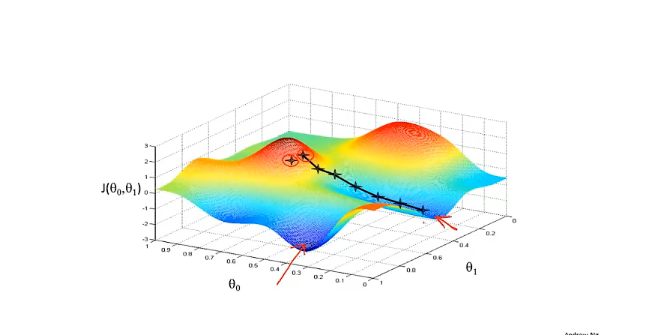
由于初始值一点点的不同,梯度下降算法可能会得到一个完全不同的局部最优解,如下图所示
其具体算法如下,$\alpha$为学习率,用来控制梯度下降时迈出多大的步子,当$\alpha$取值很小时会导致梯度下降很慢;当$\alpha$取值较大时可能会导致无法收敛甚至发散。其中$\theta_0和\theta_1$要同时更新(simultaneous update)

下图是一个直观的解释,当只有一个参数$\theta_1$时,在某点的导数为该点切线的斜率,当斜率为正时,$\theta_1$会减去一个正数使得$\theta_1$在数轴上向左移动;当斜率为负时则$\theta_1$减去一个负数,即加上一个正数,使得$\theta_1$向数轴右移动。两者皆向使代价函数取得最小值的方向移动。
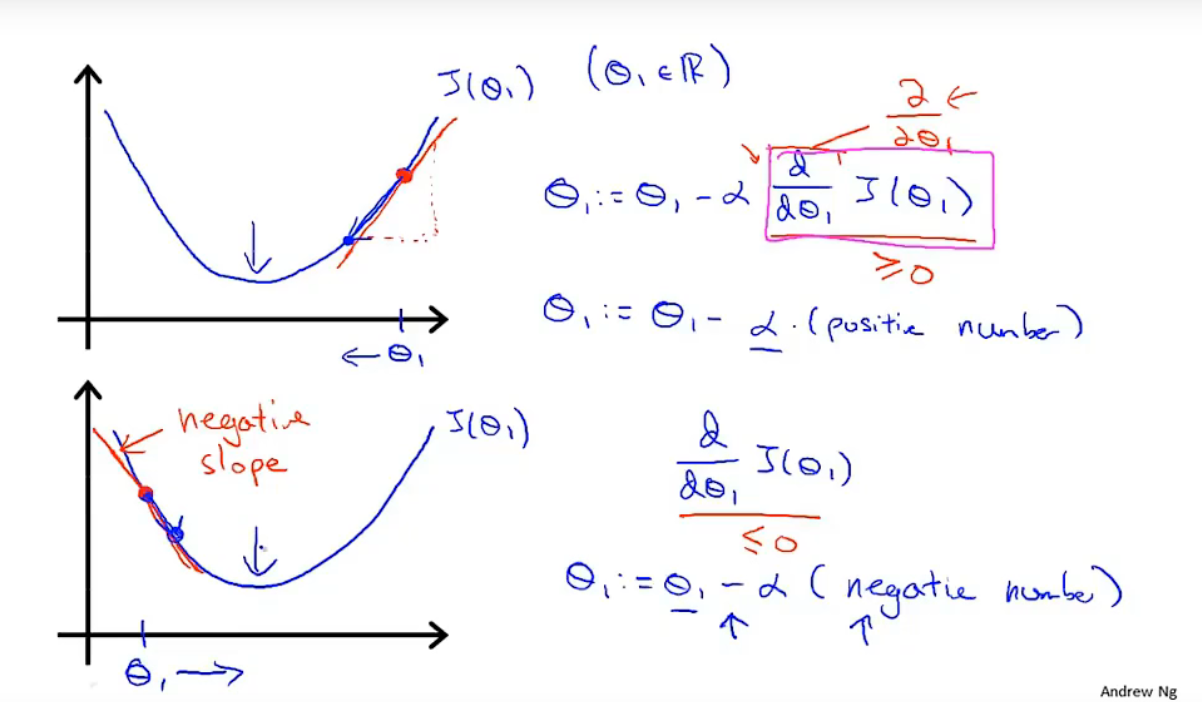
梯度下降法无须在计算过程中去调整$\alpha$的值来控制步长。当我们靠近一个局部最小值时,梯度下降法会自动采取更小的步长,因为越靠近局部最小值导数值越小 (最终趋近于0),从而使得参数的变化逐渐减小,最终收敛于最小值。
线性回归的梯度下降
假设函数为$h(x) = \theta_1x + \theta_0$,代价函数为$J(\theta_0,\theta_1)=\frac{1}{2m}\displaystyle \sum^{m}{i=1}{(h(x^i)-y^i)^2}$ ,即$J(\theta_0,\theta_1)=\frac{1}{2m}\displaystyle \sum^{m}{i=1}{(\theta_1x + \theta_0-y^i)^2}$,带入梯度下降公式可得:

这种算法也叫做Batch梯度下降算法,每次计算都要遍历整个训练集。
多功能
前面的的预测房屋价格的特征x只有一个,即房屋大小x,其假设函数为$h_\theta(x) = \theta_1x + \theta_0$
现考虑使用四个特征来预测房屋价格:楼层数,房间数,大小,房屋年龄,那么其假设函数为$h_\theta(x) = \theta_0 + \theta_1x_1 + \theta_2x_2 + \theta_3x_3 + \theta_4x_4$ ,为了方便可以表示为向量形式,假设$x_0 = 1$,那么$\vec{x} = \begin{bmatrix} x_0,x_1,x_2 ,x_3 ,x_4 \end{bmatrix}^T, \vec{\theta} = \begin{bmatrix} \theta_0,\theta_1,\theta_2 ,\theta_3 ,\theta_4 \end{bmatrix}^T$,此时假设函数可以写为$h_\theta(x) = \theta^Tx$
多元梯度下降法
$\theta$和$x$为向量,假设函数为$h_\theta(x) = \theta^Tx$,代价函数为$J(\theta) = \frac{1}{2m}\displaystyle \sum^{m}_{i=1}{(h_\theta(x^i)-y^i)^2}$,则对应多元梯度下降公式为下图所示:

特征缩放
- 特征缩放(feature scaling):通过将特征除以其最大值使得每个特征的值大约在[-1,1]的范围内(大一点小一点都可以),通过数学可以证明可以使得梯度下降的速度更加快。
- 均值归一化(mean normalization):将$x_i$用$x_i - \mu_i$代替,让特征值具有为0的平均值。

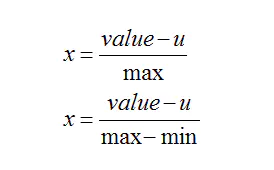
学习率$\alpha$
左边两幅图中的代价函数并没有减少,原因是学习率过大,如右图所示:
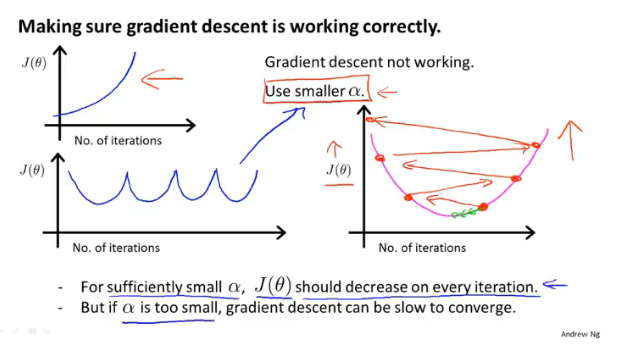
如果损失函数随着梯度下降法迭代次数的增加并没有减少,可能的原因就是学习率过高,此时需要使用更小的学习率。在线性回归中,对于充分小的学习率,代价函数函数会随着迭代次数的增加而减少最终收敛(可通过数学证明)。
总结:
- 学习率过高,代价函数的值可能会随着迭代次数的增加而增加甚至发散
- 学习率过低会导致收敛非常慢
- 尝试使用…,0.001,0.01,0.1,1…..等等当做$\alpha$,选择最优的一个
多项式回归
如果线性函数不能很好的拟合下图的数据,可以考虑使用多项式函数来拟合。
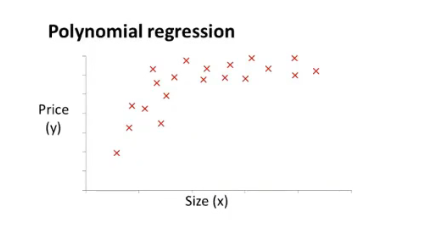
此图可以想到使用三次函数来拟合(二次函数后面会下降,而房价随着面积增大不应该还会下降),可以想到这样的形式$h_\theta(x) = \theta_0 + \theta_1(size) + \theta_2(size)^2 + \theta_3(size)^3$ 。假设函数为$h_\theta(x) = \theta_0 + \theta_1x_1 + \theta_2x_2 + \theta_3x_3$,要想让两个式子对应起来,自然想到将$x_1$特征设为$size$,将$x_2$特征设为$size^2$,将$x^3$特征设为$size^3$,此时再应用线性回归的方法就可以将一个三次函数拟合到数据上。
此处有平方项和三次方项,输入特征值可能非常大,需要使用特征缩放。
正规方程法
如果代价函数只有一个参数(一个标量)$J(\theta)$,则可以使用求导将导数置零的方法求得最值,但如果参数是一个向量$J(\theta_0,\theta_1,\theta_2,…,\theta_m)$,如果维数较大的话求偏导置零求极值可能会很困难。梯度下降法的速度可能会很慢,可以考虑使用正规方程法。
如果有m个训练实例,每个实例有n个特征,样本的特征向量为$x^{(i)} = \begin{bmatrix} x_0^{(i)},x_1^{(i)},x_2^{(i)} ,…,x_n^{(i)} \end{bmatrix}^T,$ 将特征向量组合成样本矩阵$X = [(x^{(1)})^T,(x^{(2)})^T,…,(x^{(m)})^T]$,如下图所示:
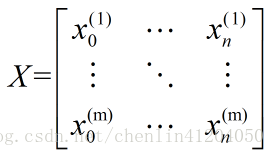
特征参数为:$\theta = \begin{bmatrix} \theta_0,\theta_1,\theta_2 ,…,\theta_n \end{bmatrix}^T$ ,输出变量为$Y = [y^{(1)},y^{(2)},…,y^{(m)}]^T$ ,此时输出变量为$Y = X\theta$,通过下图所示的变换可得特征参数的表示$\theta = (X^TX)^{-1}X^TY$,这就是使得代价函数最小化的$\theta$
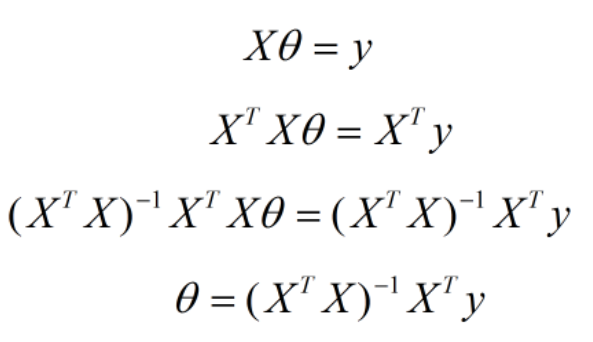
下图是房价预测的例子:

与梯度下降法的比较
梯度下降法:
- 需要选择学习率$\alpha$,可能需要很多次尝试来选择较好的学习率
- 需要很多次迭代来求参数
- 当特征数n很大时也工作良好
正规方程法:
- 不需要选择学习率
- 不需要迭代
- 需要计算$(X^TX)^{-1}$,矩阵计算的速度会随着特征数的增加而减慢,当n很大时速度慢

矩阵$(X^TX)$不可逆时的解决方法
- 删除多余的特征,如删除两个线性相关的特征的其中一个
- 使用正规化的方法
分类问题
分类问题的例子:垃圾邮件分类,网上交易,肿瘤分类等等
二分类问题
二分类问题尝试预测的变量y是只有两个取值的变量0或1,0代表负类(恶性肿瘤),1代表正类(良性肿瘤)
逻辑回归算法
我们希望分类器的输出值在[0,1]之间。此时可以设假设函数$h_\theta(x) = g(\theta^{T}x)$ ,其中$g(x)$为sigmoid函数。
sigmoid函数(logistic函数):$g(z) = \frac{1}{1+e^{-z}}$ ,随着z值的增大函数值会逼近于1,随着z值减小函数值会逼近于0。函数图像如下图所示
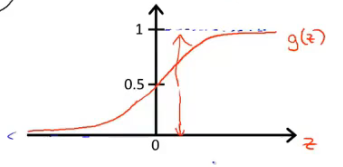
有了sigmoid函数后,$g(z)$的值在0和1之间,$h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}}$的值也会在0和1之间。此时可以用参数$\theta$来拟合数据。
对假设函数输出的解释:根据输入特征x估计y=1的可能性。下面的例子是根据病人的肿瘤大小来估计y=1(肿瘤是恶性)的可能性,根据输出可知此时有70%的概率是恶性肿瘤。
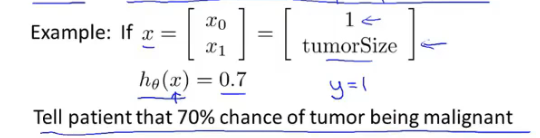
假设函数更加正式的数学表达式:$h_\theta(x) = P(y=1|x;\theta)$,如果要知道y=0的概率,直接计算$P(y=0|x;\theta)=1-P(Y=1;x;\theta)$即可。
决策边界
假设如果$h_\theta(x)\ge0.5$则预测y=1,如果$h_\theta(x)<0.5$就预测y=0。根据sigmoid函数图像,即$\theta^Tx\ge0$预测y=1,否则预测y=0。
例子1:现状假设有一个训练集,图如下所示。假设函数为$h_\theta(x)=g(\theta_0+\theta_1x_1+\theta_2x_2)$,假设参数向量已经拟合好$\vec{\theta}=[-2,1,1]^T$。此时当$-3+x_1+x_2\ge0$就预测y=1,否则预测y=0。此时的决策边界是图中洋红色的直线$x_1+x_2=3$,直线右半平面为y=1区域,其他区域为y=0区域。
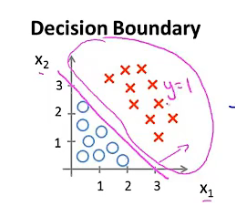
- 注意:决策边界为假设函数的一个属性,决定于其参数而不是数据集的属性。一旦有确定的参数$\theta$,我们将完全确定决策边界。无需通过画出训练集来确定决策边界。
例子2:训练集的图如下图所示。假设函数为$h_\theta(x)=g(\theta_0+\theta_1x_1+\theta_2x_2+\theta_3x_1^{2}+\theta_4x_2^{2})$。假设参数向量已经拟合好$\vec{\theta}=[-1,0,0,1,1]^T$。此时的决策边界为$x_1^2+x_2^2=1$,为以原点为中心,半径为1的圆。
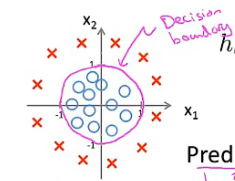
通过在特征中增加更复杂的多项式可以得到更复杂的边界。
logistic回归的代价函数
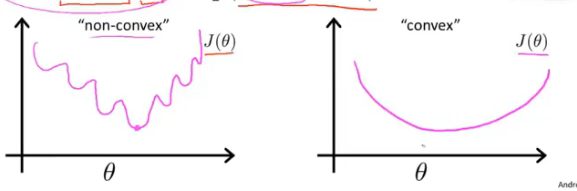
代价函数为$J(\theta)=Cost(h_\theta(x^{(i)}),y^{(i)})$。如果使用之前线性回归的$Cost(h_\theta(x^{(i)}),y^{(i)})=\frac{1}{2}(h_\theta(x)-y)^2$,此时的代价函数是关于参数$\theta$的非凸函数,会出现很多局部最优值,使用梯度下降法不能保证收敛到全局最优值。需要使用一个凸函数作为代价函数,如下图所示:
从而logic回归的代价函数为如下所示:
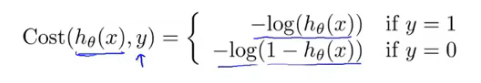
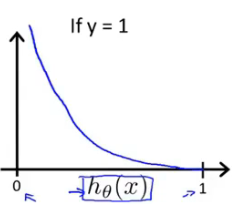
假设预测y=1,代价函数的图像如下,随着$h_\theta(x) $->1,代价函数的值会趋向于无穷,预测y=0则相反。
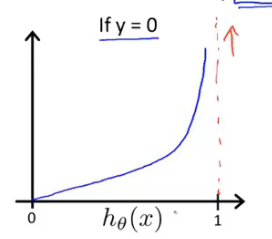
将两个式子写在一起则为$Cost(h_\theta(x^{(i)}),y^{(i)})=-ylog(h_\theta(x))-(1-y)log(1-h_\theta(x))$,此时可得logistic回归的代价函数$J(\theta) = \frac{1}{m}\displaystyle\sum^{m}_{i=1} Cost(h_\theta(x^{(i)}),y^{(i)})=-\displaystyle\sum^{m}_{i=1}[y^{(i)}log(h_\theta(x^{(i)}))+(1-y^{(i)})log(1-h_\theta(x^{(i)}))]$
- 注:这个式子是通过统计学中的极大似然法得到的(见《统计学习方法》)
为了拟合出让$J(\theta)$取得最小值的参数$\theta$,此时的策略为$minJ(\theta)$ ,方法仍然为梯度下降法。(此处画蓝线的地方求和符号前少了个1/m)

求导过程:

多元分类:一对多
例子:将邮件分类到不同种类的文件夹,天气分类…二元分类和多元分类的数据集区别如下
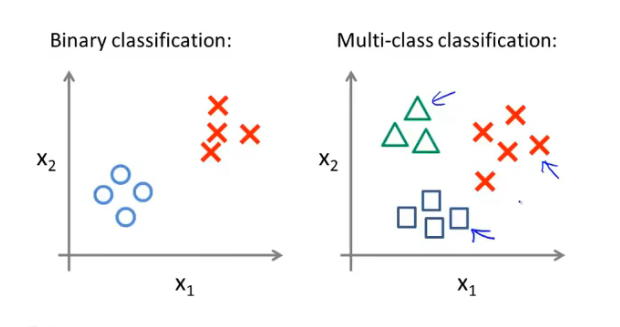
可以使用二元分类的思想来解决多元分类的问题,以三个分类为例,方法是将一对三分类问题分为三个独立的二元分类问题。对每个分类$i$拟合一个logistic回归分类器$h_\theta^{(i)}(x)$来预测$y=i$的可能性。比如在三个分类器输入x运行,然后选择三个分类器中输出概率最大的那个就是预测的y的值。
过拟合问题
什么是过拟合?
- 如果我们有很多特征,训练到的假设函数也许可以很好地拟合训练集(代价函数接近于0),但是不能够**泛化(generalize)**到新的样本之中(无法预测新样本的价格)。
- 泛化(generalize):一个假设模型应用到新样本的能力。
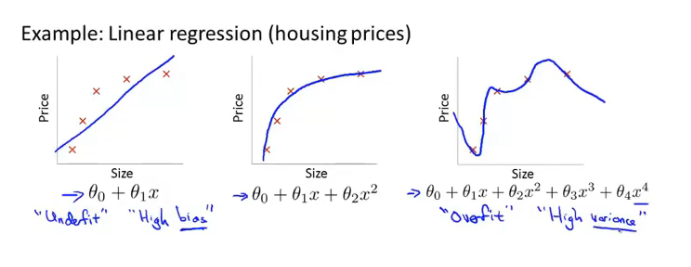
下面是欠拟合(高偏差),正好,过拟合(高方差)的两个例子,第一个是回归问题,第二个是分类问题:
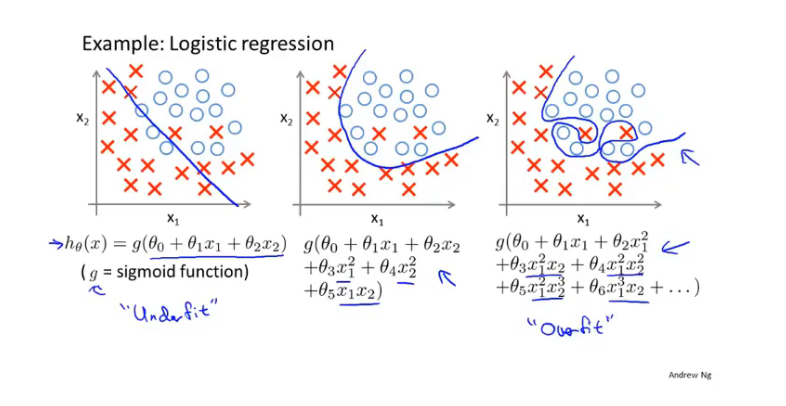
解决方法:
- 减少特征的数量:人工检查变量清单,选择保留哪些特征;使用模型选择算法。
- 正则化:保留所有特征,但是减少量级或参数$\theta$的大小。当我们有许多特征时(每一个变量都或多或少是有用的)工作良好。
正则化
上面回归问题中如果模型是:$h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x_2^2+\theta_3x_3^3+\theta_4x_4^4$
从之前的两个例子可知,是高次项导致了过拟合的产生,如果能够让高次项的系数接近于0的话就能很好的拟合。正则化就是在一定程度上减少这些参数$\theta$的值。
方法:在代价函数中加入对$\theta_3和\theta_4$的惩罚,在最小化代价时会选择较小的$\theta$。修改后的代价函数:
$\underset{\theta }{\mathop{\min }}\,\frac{1}{2m}[\sum\limits_{i=1}^{m}{{{\left( {{h}_{\theta }}\left( {{x}^{(i)}} \right)-{{y}^{(i)}} \right)}^{2}}+1000\theta _{3}^{2}+10000\theta _{4}^{2}]}$通过这样的代价函数选择出的${\theta_{3}}$和${\theta_{4}}$ 对预测结果的影响就比之前要小许多。假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度。
这样的结果是得到了一个较为简单的能防止过拟合问题的假设:$J\left( \theta \right)=\frac{1}{2m}[\sum\limits_{i=1}^{m}{{{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})}^{2}}+\lambda \sum\limits_{j=1}^{n}{\theta_{j}^{2}}]}$其中$\lambda $又称为正则化参数(Regularization Parameter),$\lambda \sum\limits_{j=1}^{n}{\theta_{j}^{2}}$为正则化项。
- 注:根据惯例,我们不对${\theta_{0}}$ 进行惩罚。
如果$\lambda$选择过大会导致所有参数最小化,从而导致模型变为$h_\theta(x)=\theta_0$,变成了一条直线,造成欠拟合。下图是原模型,正则化后的模型和$\lambda$选择过大的模型:
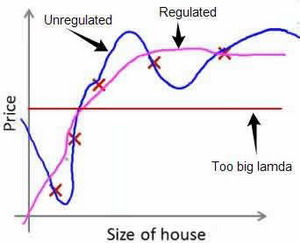
所以对于正则化,我们要取一个合理的 𝜆 的值,这样才能更好的应用正则化。
线性回归的正则化
正则化线性回归的代价函数:$J\left( \theta \right)=\frac{1}{2m}[\sum\limits_{i=1}^{m}{{{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})}^{2}}+\lambda \sum\limits_{j=1}^{n}{\theta_{j}^{2}}]}$
正则化线性回归的梯度下降算法如下(其中不惩罚$\theta_0$,所以有两个式子):
$Repeat$ $until$ $convergence${ ${\theta_0}:={\theta_0}-a\frac{1}{m}\sum\limits_{i=1}^{m}{(({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{0}^{(i)}})$ ${\theta_j}:={\theta_j}-a[\frac{1}{m}\sum\limits_{i=1}^{m}{(({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{\left( i \right)}}+\frac{\lambda }{m}{\theta_j}]$ $for$ $j=1,2,...n$ }对上面的算法中$ j=1,2,…,n$ 时的更新式子进行调整可得:
${\theta_j}:={\theta_j}(1-a\frac{\lambda }{m})-a\frac{1}{m}\sum\limits_{i=1}^{m}{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{\left( i \right)}}$可以看出,正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的基础上令$\theta $值减少了一个额外的值。
对应正规方程的版本如下,图中的矩阵为$(n+1)*(n+1)$:
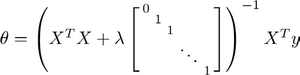
logistic回归的正则化
和线性回归同理,也对代价函数增加一个正则化项,得到正则化logistic回归的代价函数:
$J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{[-{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)-\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]}+\frac{\lambda }{2m}\sum\limits_{j=1}^{n}{\theta _{j}^{2}}$正则化后的模型为下图洋红色的线:
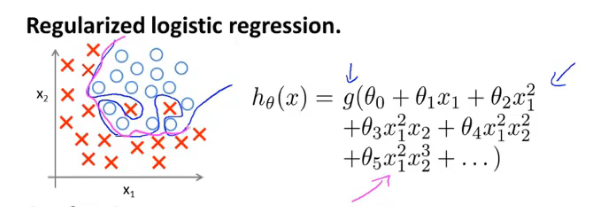
正则化logistic回归的梯度下降算法如下(其中不惩罚$\theta_0$,所以有两个式子):
$Repeat$ $until$ $convergence${ ${\theta_0}:={\theta_0}-a\frac{1}{m}\sum\limits_{i=1}^{m}{(({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{0}^{(i)}})$ ${\theta_j}:={\theta_j}-a[\frac{1}{m}\sum\limits_{i=1}^{m}{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{\left( i \right)}}+\frac{\lambda }{m}{\theta_j}]$ $for$ $j=1,2,...n$ }注:虽然正则化的逻辑回归中的梯度下降和正则化的线性回归中的表达式看起来一样,但由于两者的${h_\theta}\left( x \right)$不同所以还是有很大差别。
神经网络
非线性假设
之前我们已经看到过,使用非线性的多项式项,能够帮助我们建立更好的分类模型。
假设我们有非常多的特征,例如大于100个变量,我们希望用这100个特征来构建一个非线性的多项式模型,结果将是数量非常惊人的特征组合,即便我们只采用两两特征的组合$(x_1x_2+x_1x_3+x_1x_4+…+x_2x_3+x_2x_4+…+x_{99}x_{100})$,我们也会有接近5000个组合而成的特征。这对于一般的逻辑回归来说需要计算的特征太多了。

简单的logistic回归算法并不是一个在n很大时学习复杂的非线性假设的好方法,因为特征过多。
例如根据50*50像素的图片来判断是否是汽车,这是个分类问题。输入特征为图片的像素,而一张图片有2500个像素,即n = 2500,此时特征向量的维数为2500,每个像素点的值为0到255之间(这还只是灰度图像,如果使用的是RGB彩色图像,包含红绿蓝三种颜色,此时n=7500)。此时如果要使用多项式来拟合,进一步将两两特征组合成一个多项式模型,则会有约${{2500}^{2}}/2$个(接近3百万个)特征。
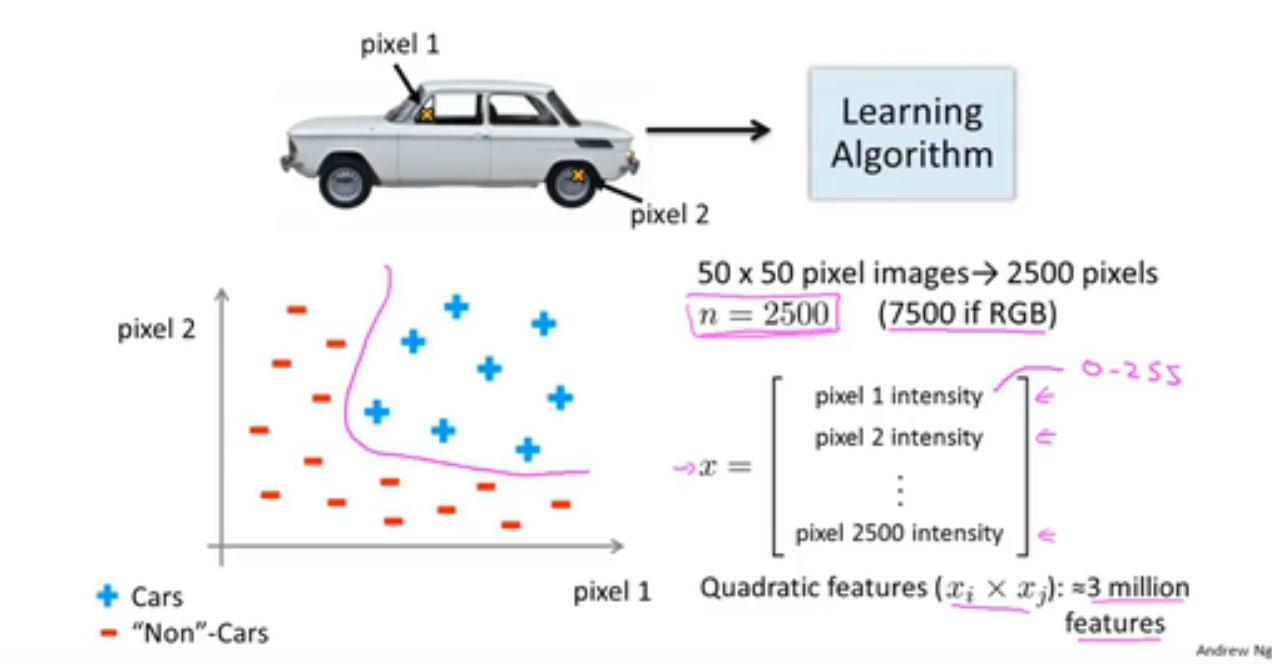
普通的逻辑回归模型,不能有效地处理这么多的特征,这时候我们需要神经网络。
模型展示
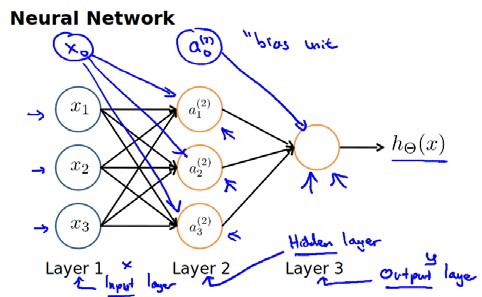
神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。这些神经元(也叫激活单元,activation unit)采纳一些特征作为输出,并且根据本身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,参数又可被成为权重(weight)。$x_0$为偏置
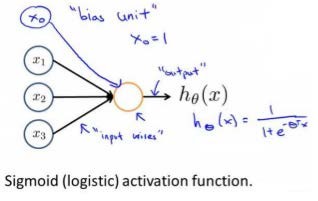
我们设计出了类似于神经元的神经网络,效果如下。其中$x_1$, $x_2$, $x_3$是输入单元(input units),我们将原始数据输入给它们。
$a_1$, $a_2$, $a_3$是中间单元,它们负责将数据进行处理,然后呈递到下一层。
最后是输出单元,它负责计算${h_\theta}\left( x \right)$。
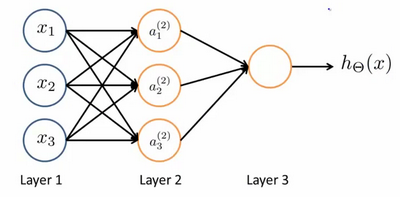
神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。下图为一个3层的神经网络,第一层成为输入层(Input Layer),最后一层称为输出层(Output Layer),中间一层成为隐藏层(Hidden Layers)。我们为每一层都增加一个偏差单位(bias unit):
下面引入一些标记法来帮助描述模型:
$a_{i}^{\left( j \right)}$ 代表第$j$ 层的第 $i$ 个激活单元。${{\theta }^{\left( j \right)}}$代表从第 $j$ 层映射到第$ j+1$ 层时的权重的矩阵,例如${{\theta }^{\left( 1 \right)}}$代表从第一层映射到第二层的权重的矩阵。其尺寸为:以第 $j+1$层的激活单元数量为行数,以第 $j$ 层的激活单元数加一为列数的矩阵。例如:上图所示的神经网络中${{\theta }^{\left( 1 \right)}}$的尺寸为 3*4。 对于上图所示的模型,激活单元和输出分别表达为: $a_{1}^{(2)}=g(\Theta _{10}^{(1)}{{x}_{0}}+\Theta _{11}^{(1)}{{x}_{1}}+\Theta _{12}^{(1)}{{x}_{2}}+\Theta _{13}^{(1)}{{x}_{3}})$ $a_{2}^{(2)}=g(\Theta _{20}^{(1)}{{x}_{0}}+\Theta _{21}^{(1)}{{x}_{1}}+\Theta _{22}^{(1)}{{x}_{2}}+\Theta _{23}^{(1)}{{x}_{3}})$ $a_{3}^{(2)}=g(\Theta _{30}^{(1)}{{x}_{0}}+\Theta _{31}^{(1)}{{x}_{1}}+\Theta _{32}^{(1)}{{x}_{2}}+\Theta _{33}^{(1)}{{x}_{3}})$ ${{h}_{\Theta }}(x)=g(\Theta _{10}^{(2)}a_{0}^{(2)}+\Theta _{11}^{(2)}a_{1}^{(2)}+\Theta _{12}^{(2)}a_{2}^{(2)}+\Theta _{13}^{(2)}a_{3}^{(2)})$上面进行的讨论中只是将特征矩阵中的一行(一个训练实例)喂给了神经网络,我们需要将整个训练集都喂给我们的神经网络算法来学习模型。
我们可以知道:每一个$a$都是由上一层所有的$x$和每一个$x$所对应的权重所决定的。(我们把这样从左到右的算法称为前向传播算法( FORWARD PROPAGATION ))
相对于使用循环来编码,利用向量化的方法会使得计算更为简便。
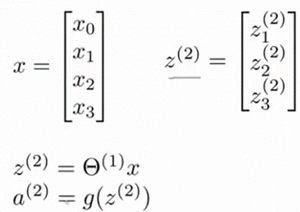
神经网络很像logistic回归,但输入的特征是通过隐藏层(Layer2)计算的数值。
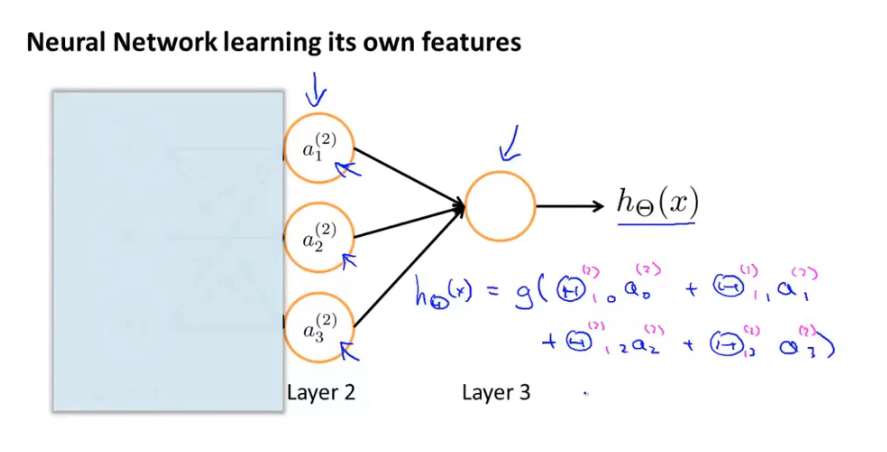
我们可以把$a_0, a_1, a_2, a_3$看成更为高级的特征值,也就是$x_0, x_1, x_2, x_3$的进化体,并且它们是由 $x$与$\theta$决定的,因为是梯度下降的,所以$a$是变化的,并且变得越来越厉害,所以这些更高级的特征值远比仅仅将 $x$次方厉害,也能更好的预测新数据。
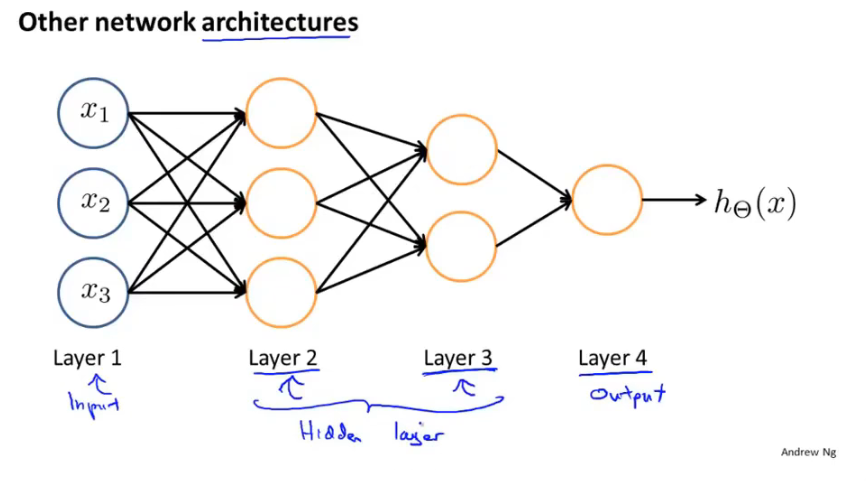
下面是一个不同的神经网络架构,有两个隐藏层。
普通的逻辑回归只能使用原始的输入特征x或他们的二项式组合,但神经网络中,原始特征只是输入层,通过隐藏层可以得出一系列新特征,可以逐渐构造出越来越复杂的函数,也能得到更加厉害的特征值。
神经网络中,单层神经元(无中间层)的计算可用来表示逻辑运算,比如逻辑与(AND)、逻辑或(OR)。XNOR神经元可以通过and和or神经元来组合:
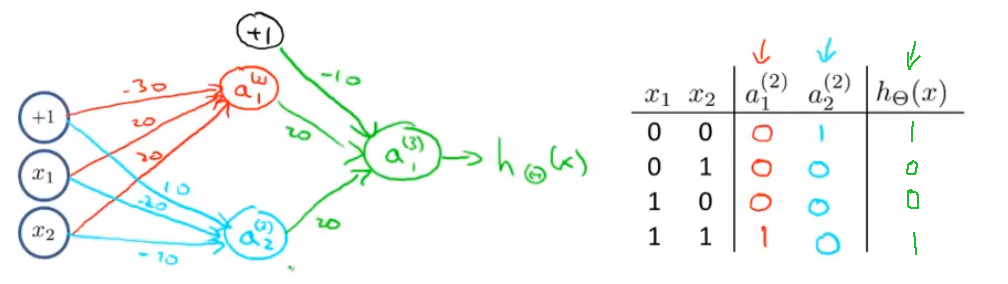
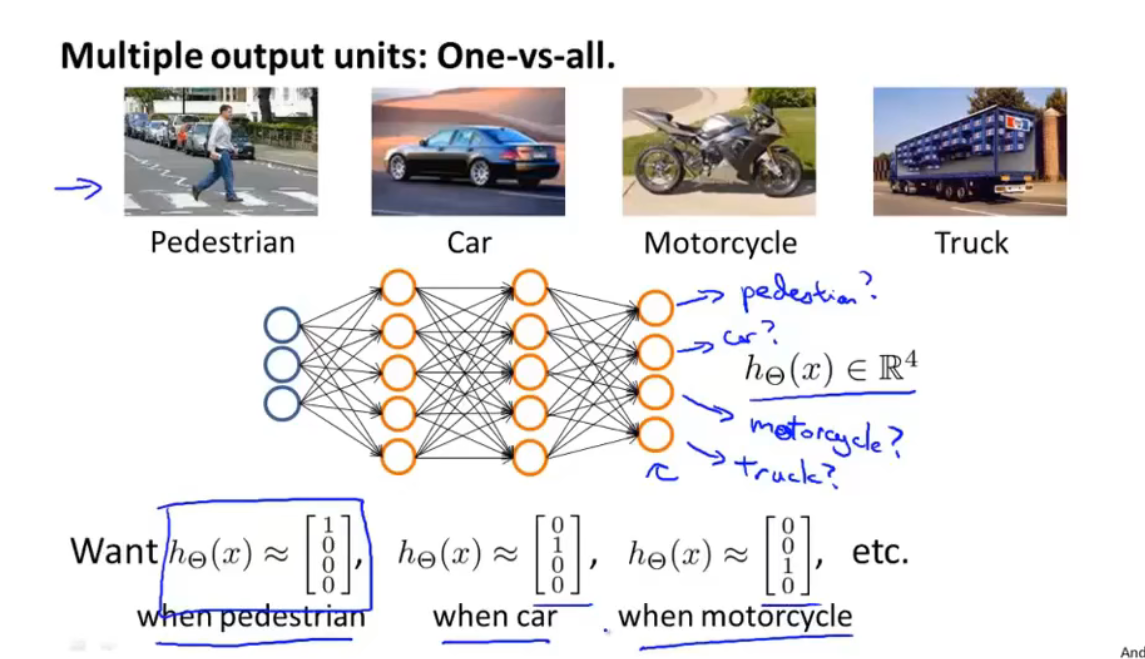
多元分类
在神经网络中实现多元分类是对之前的一对多方法的扩展。
如果要通过图像来辨别出哪些是行人,汽车,摩托车或者货车,我们所要做的就是建立一个有四个输出单元的神经网络,每个输出单元代表一个分类,如下图所示: