
A Storage-Effective BTB Organization for Servers
Abstract
足够大的BTB使前端能够准确地解决即将到来的执行路径并适当地引导指令获取,还能实现高效的指令预取,从而消除很大一部分L1-I缺失。由于这些原因,商业处理器为BTB分配了大量的存储容量。
这篇论文的工作主要是通过优化btb条目的组织来减少btb的存储容量需求,主要方法是指存储分支目标地址的偏移量而不是整个分支目标地址或者压缩的地址。
我们的最终设计,称为BTB-X,使用8路组相联的BTB的不同大小的方式,使其能够在相同的存储预算下,比传统的BTB跟踪2.24倍的分支,比存储优化的最先进的BTB组织方式,称为PDede,跟踪1.3倍的分支。
Introduction
BTB处于高性能cpu前端的中心,有三个关键原因:它决定了要获取的指令流,它为分支方向预测器确定了分支,并影响了L1-I的击中率。
BTB与方向预测器一起实现了一类重要的指令预取器,称为 “指令预取”(FDIP),它依靠BTB来发现L1-I预取候选。
考虑到捕捉现代工作负载的大型分支工作集的重要性,商用CPU的BTB具有巨大的容量。
先前的工作
方法
为了降低BTB的存储成本,先前的工作集中在压缩分支目标地址上。因为分支目标的存储需求占 BTB 存储需求的主要部分
一个页面内的所有分支目标共享相同的页码,通过每页只存储一次页码而不是每个目标存储一次,可以大大降低BTB的存储需求:
- 将BTB划分为两个结构,即Main-BTB和Page-BTB
- Main-BTB存储页偏移量和一个指向存储页号的Page-BTB条目的指针
PDede,进一步观察到目标地址跨越的区域明显少于页面,其中一个区域是一组连续的页面。它进一步划分了BTB,并引入了区域BTB。
通过对一个页/区域内的所有分支只存储一次页/区域号,这些BTB避免了信息的重复,从而降低了存储需求。
问题
它们引入了几个复杂的问题,增加了访问延迟和功耗:
- 访问BTB时,首先访问Main-BTB以获得指向Page-BTB或Region-BTB的指针,然后才可以访问这些BTB,增加了延迟;
- 在分配一个新的BTB条目时,需要搜索Page-BTB或Region-BTB,以检查目标地址的页面/区域编号是否已经存在,由于页/区号可以在Page/Region-BTB中的任何位置,因此需要进行全相联的搜索,这增加了BTB的功耗
BTB-x
关键见解是,目标偏移量分布不均,但往往需要比完整甚至压缩的目标地址少得多的比特来表示:
- 54%的动态分支只需要6位或更少的偏移量编码,而仅有1%的分支需要25位或更多的偏移量来存储它们
我们调整组相联 BTB 的不同路(way)的大小以保存不同数量的偏移位,这样每条路只存储那些目标偏移可以用一定数量的位编码的分支。
这项工作做出的贡献:
- 表明存储分支目标偏移量而不是完整或压缩的目标地址可以显着节省 BTB 存储空间
- 表明目标偏移量大小分布不均匀,分别需要 0-6 位、7-10 位和 11-25 位来编码 54%、22% 和 23% 的分支的偏移量。因此,单一大小的偏移字段不能提供存储最优解
- 介绍了 BTB-X,一种简单且存储效率高的 BTB 组织方式
- 在相同的存储预算下,BTBX 可以容纳比传统 BTB 和 PDede(最先进的 BTB)多大约 2.24 倍和 1.3 倍的分支
BACKGROUND AND MOTIVATION
背景
分支指令的 BTB miss意味着未检测到分支并且前端继续按顺序取指,顺序路径是否正确取决于miss的分支的实际方向。
当处理器最终检测到错误路径时,BTB 中miss的分支之后的所有指令都被冲刷,重定向到分支目标进行取指,并且流水线被正确路径指令填充。
指令预取器(FDIP)是L1 指令cache预取器,本质上依赖 BTB 来识别预取候选者。
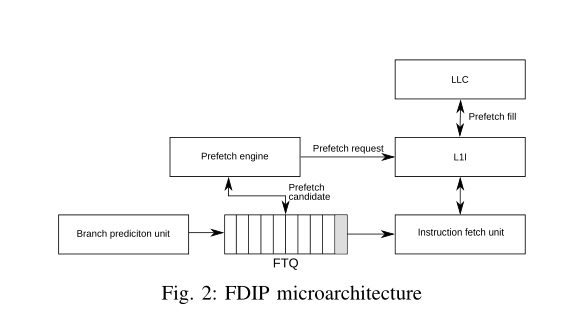
取指目标队列 (FTQ) 将分支预测单元和取指单元分离。
为了使 FDIP 有效,BTB 需要容纳分支工作集,否则频繁的 BTB miss将FTQ中填充大量错误的错误路径上的指令地址,导致 FDIP 预取错误的路径上的指令。这是商业处理器部署大量 BTB 的关键原因之一
动机
随着服务器应用程序的指令足迹不断扩大,谷歌网络搜索工作负载也反映出一种趋势,其指令足迹以每年 27% 的速度增长,BTB 大小及其存储开销注定会在未来增加。迫切需要研究存储有效的 BTB 组织,以在不需要高昂的区域预算的情况下克服前端瓶颈
BRANCH TARGET DISTANCE ANALYSIS
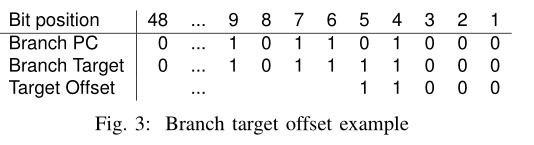
论文中的偏移量取n 个低阶目标位而不是分支指令的PC 和目标地址之间的数值距离(target - PC)的原因:
- 可以简单的移位分支指令的PC与检索到的偏移量拼接来获得完整的分支目标地址。相反,使用数值距离作为偏移量需要一个 48 位加法器来从偏移量中恢复完整目标。
例如下面的例子中目标地址和分支指令的pc(虚拟地址)只有第五位不同,因此偏移量可以取低5位11000,又由于4字节对齐,因此低2位总是0,因此偏移量取110即可。得到分支目标地址只需要将pc的高位和偏移量进行拼接即可得到目标地址。这样大大减少了分支目标地址的存储需求
下图展示了分支目标地址的偏移量的分布,短偏移量在分布中占主导地位,54% 的分支只需要 6 位或更少的偏移量,另外 22% 的分支只需要 7 到 10 位来表示它们的偏移量,只有区区 1% 的分支需要超过 25 位的偏移量。返回指令从ras中获取目标指令,因此假设返回指令的偏移量为0。
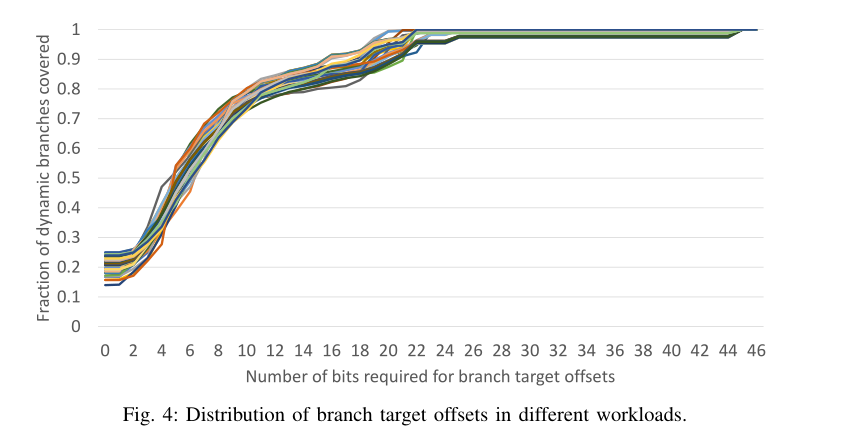
结果表明:为完整的 46 位目标地址保留空间会导致 BTB 存储的利用率严重不足
本章的结论:
- 大多数分支指令的目标在虚拟地址空间中相对靠近分支指令本身,以分支指令的偏移量的形式存储到目标的距离可以提供显着的存储节省。
- 目标偏移量大小分布不均匀,分别需要 0-6 位、7-10 位和 11-25 位来编码 54%、22% 和 23% 的分支的偏移量。
STATE-OF-THE-ART BTBS AND THEIR LIMITATIONS
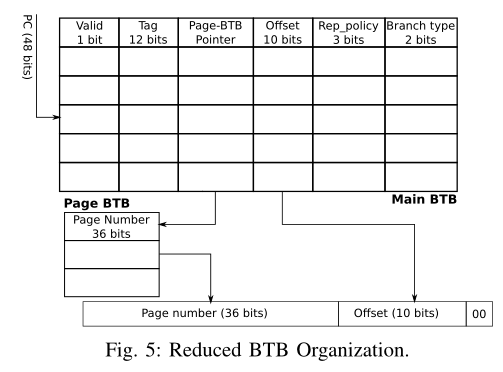
Reduced BTB(R-BTB)
发现在一个page内的分支目标地址都有相同的page number,如果在BTB中每个entry都保存这个page number,那么会浪费空间
R-BTB将page number提取出来放在一个单独的page BTB中,则Main BTB中原先保存完整page number的field就可以用一个几位的指针来代替,指针指向page BTB,因此可以节省大量的空间
PDede
PDede在R-BTB的基础上注意到,pages往往会形成空间区域(region)。其中region是由连续的page组成的,因此可以进一步从page number中提取出region number进一步节省空间,因此PDede将region number保存在一个region BTB中,Main BTB中保存region BTB的指针
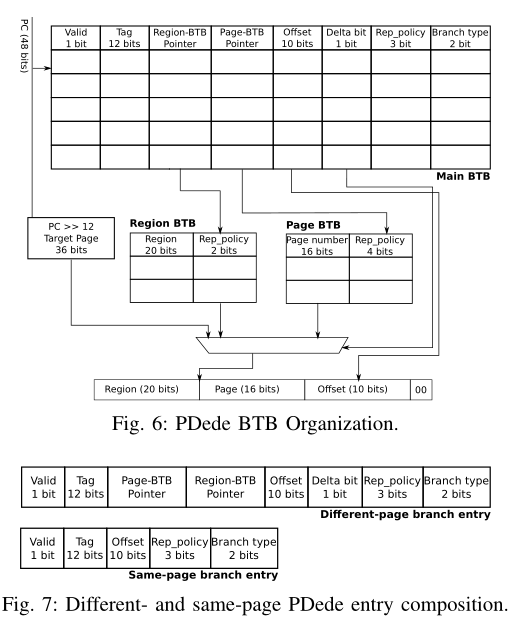
同时PDede为了进一步节省空间,当分支指令和他的目标地址在同一个page中时,PDede不存储page number和region number
缺点
- indirection:R-BTB和PDede存储的是指针,需要额外的访问延迟,尽管PDede通过两种不同的BTB entry来一定程度上减少了额外的访问
- 全相联的搜索:在分配一个新的BTB entry时,需要全相联搜索region BTB和page BTB来查询目标page和region是否已经存在,这会带来功耗问题。PDede通过限制page BTB的entry数目来尽量避免这个问题
- 存储利用率并没有最优化:偏移量都是定长的10位,但是54%的目标偏移量都只需要6位或更少就可以了
BTB-X
btb-x通过设置组相联中不同路具有不一样的偏移量长度来适应目标偏移量大小的不均匀分布问题。同时使用一个非常小的直接映射btb(btb-xc)来保存完整的目标地址,因为在BTB-x中为这1%的分支保留一路是没有必要的
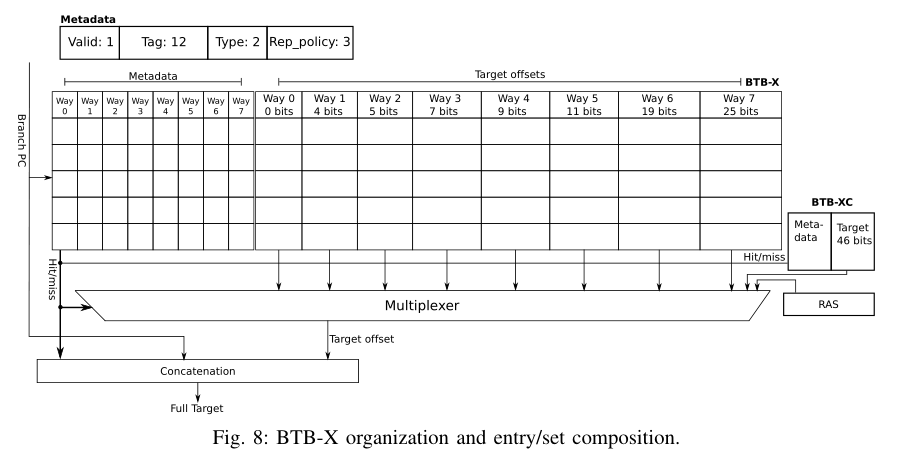
BTB-x和btb-xc的查找是同时进行的,如果在btb-xc中找到了对应项就使用btb-xc的目标地址,否则根据匹配到的路来决定拼接pc的多少位来组成目标地址,例如匹配到了way-7,则使用pc的高21位和way-7提供的25 bits的offset进行拼接组成目标地址
btb-x在分配新的entry时,分支目标偏移量的位数决定了其所分配到的way,例如,如果一个分支需要 20 位作为它的目标偏移量,它就不能分配到 way-0 到 way-6
BTB-X 使用稍微修改过的LRU替换策略,将其修改为只比较能够容纳目标偏移量的entry的LRU计数器,并替换其中最近最少使用的entry
EVALUATION
所使用模拟器:champsim
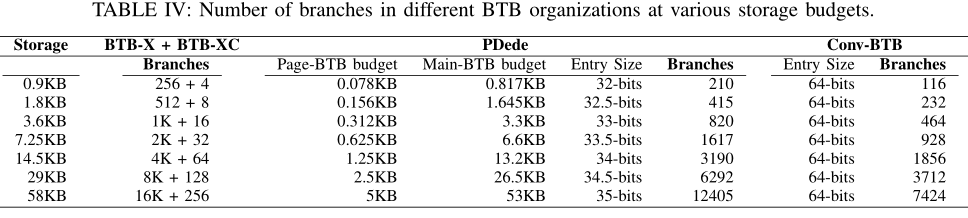
容纳分支数量比较
首先比较不同的 BTB 组织(Conv-BTB、PDede 和 BTB-X)在给定的存储预算中可以容纳的分支数量,如下图所示,可以得出BTB-X 存储的分支明显多于任何其他 BTB 组织方式
MPKI的比较
然后比较了MPKI(misses per 1000 instructions )和性能提升,如下图所示
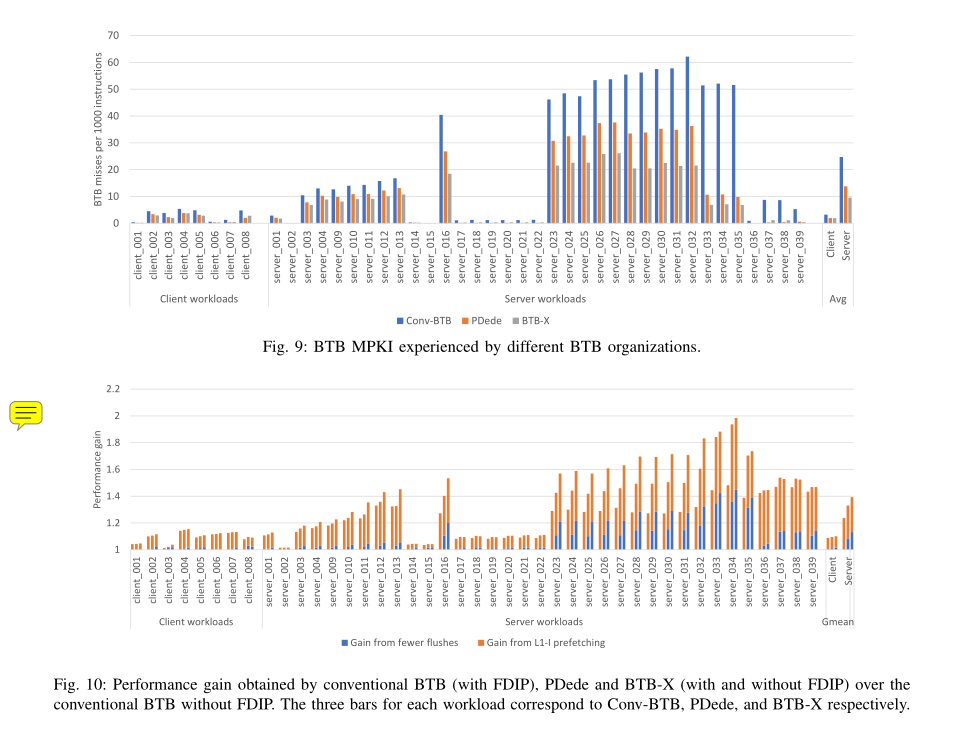
首先分析MPKI:
- 服务器工作负载的 MPKI 明显高于客户端工作负载,因为它们具有大量指令和分支足迹
- 与传统 BTB 和 PDede 相比,BTB-X 提供的 MPKI 低得多,尤其是在服务器工作负载方面
然后分析性能提升,baseline是没有FDIP的conv-btb,第一个柱状图是带了FDIP的conv-btb:
- PDede 和 BTB-X 条将性能增益分为更少的流水线刷新贡献和更好的指令预取,原因是能够容纳更多的分支
- BTB-X 在服务器工作负载上比baseline提供 39% 的几何平均增益
- BTB-X 在服务器 023 到服务器 32 上的性能全面优于 PDede 和 Conv-BTB,这是由于这些工作负载的分支工作集适配btb-x的大小(其能容纳的分支数目多余其余两个)
- BTB MPKI 降低,这不仅减少了流水线的冲刷,而且还使 FDIP 保持在正确的预取路径上更长时间
- FDIP受益于BTB大小的增长
- 所有三个BTB的组织方式在客户端工作负载上的表现相似,这是因为他们的分支工作集主要适合baseline Conv-BTB,而 PDede 和 BTB-X 中的额外entry不会带来太多性能优势
这些结果表明,通过在给定的存储预算中容纳更多分支,BTB-X 不仅减少了流水线刷新,而且还改进了指令预取,两者都带来了更好的性能
能耗的比较
- BTB-x的每次读写能耗要小于PDede,因为PDede要额外访问Page BTB和Region BTB,但是两者的差距不大
- BTB-x的总能耗要小于PDede
- 尽管每次读写的能耗相差不大,但是因为 PDede 由于其较高的 MPKI 而经常走在错误的执行路径上导致更高的能量消耗,
- 此外,PDede 需要处理比 BTB-X 更多的 BTB 写入,因为它拥有更少的分支,这导致频繁替换
每次访问延迟的比较
- BTB-x的访问延迟要略低于传统BTB(conv-btb),要优于PDede
比较不同存储预算下性能的比较如下图所示,此处的baseline为0.9KB的带FDIP的conv-btb
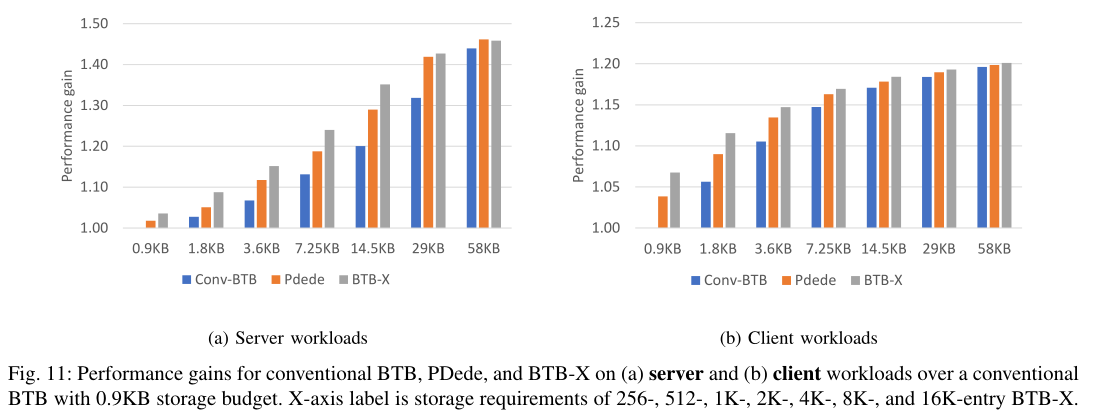
- 在 14.5KB 的预算下,BTB-X 比baseline提供了 35% 的性能增益,而 PDede 和 Conv-BTB 分别为 29% 和 20%
- 在大的BTB 存储预算下,许多工作负载的分支工作集开始适应可用的 BTB 容量,此时 BTB-X 与其他两个设计之间的性能差距缩小
- 由于客户工作负载中的指令工作集较小,三个 BTB 之间的性能差距在客户端跟踪上较早趋于平缓
- BTB-X 的性能优于传统 BTB,即使它的存储预算仅为传统同类产品的一半,造成这种现象的原因是 BTB-X 比同等存储预算的 ConvBTB 多容纳 2.24 倍的entry
分析更多工作负载中的目标偏移量分布
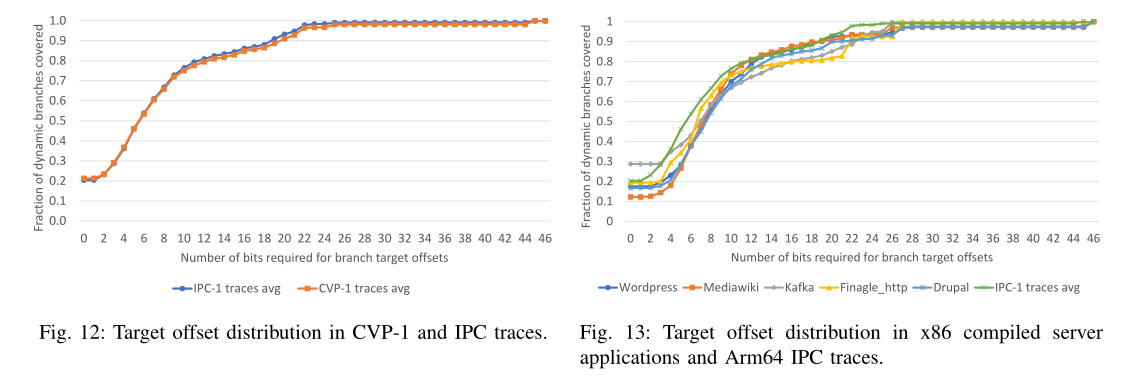
- 短偏移量在分支偏移量分布中占主导地位
- x86追踪需要稍大的偏移量(多1或2位)来实现与Arm64(CVP-1和IPC-1)追踪类似的动态分支覆盖,这是因为x86为变长指令,offset存储的是距离分支指令的字节数而不是指令数
- BTB-X的存储优势对于x86来说比Arm64略低,由于8路BTB-X中的每一路需要覆盖大约12.5%的分支,因此每一路所存储的偏移量变大了
- 对于x86,BTB-X仍然比Conv-BTB多存储2.18倍的分支(对于Arm是2.24倍)。与PDede相比,BTB-X在0.9KB的存储预算下存储了1.21倍的分支(Arm64为1.24倍),在58KB的存储预算下存储了1.31倍的分支(Arm64为1.34倍)
结论
- 对BTB存储成本贡献最大的是存储分支目标的成本
- 因为大多数分支的目标都离分支本身比较近,BTB的存储成本可以通过存储目标偏移量而不是完整的甚至是压缩的分支目标地址来大幅降低
- 超过99%的偏移量可以用存储完整目标所需的最多一半的比特来表示
- 提出了一种具有存储效率的BTB组织,称为BTB-X,它用目标偏移量代替目标地址
- BTB-X是一个8路集合关联的BTB,使用不同大小的方式,每路存储不同长度的偏移量,从而说明偏移量长度的不均匀分布
- BTBX能够在相同的存储预算内,比传统BTB多存储约2.24倍的分支,比最先进的BTB组织多存储1.3倍的分支
我的思考
本文要解决的问题:BTB存储开销不仅很高,而且还在快速增长,需要进行优化
改进目标:在不增加BTB复杂性的情况下降低BTB存储需求
如何改进:在当前最优的btb存储优化方式pDede上进行改进和优化
作者是如何思考的?
- 当前最优的方法是优化分支目标地址的存储需求:方法是只存储距离区域的偏移量,然后存储一个指向区域号的指针
- 发现当前方法存在的问题:每次访问BTB需要访问两次,需要额外访问一次Region-BTB,增加了延迟和功耗
- 要想减少延迟和功耗,就需要消除额外访问Region-BTB的需求
- 只存储距离分支指令的偏移量可否?这即减少了存储容量又消除了额外的访问
- 因此去研究偏移量的特点,发现大多数分支指令的目标在虚拟地址空间中相对靠近分支指令本身和目标偏移量大小分布不均匀两个特点,以分支指令的偏移量的形式存储到目标的距离可以显著减少存储需求

