
补充知识
TBR的核心思想是:将帧缓冲分割为一小块一小块(tile),然后逐块进行渲染,TBR (Tile-Based Rendering)是基于Tile(块)的绘制,就是将以往IMR与系统内存进行频繁交互的过程迁移到高速On-Chip Buffer中完成,On-Chip Buffer的大小与tile一致
光栅化的本质是坐标变换、几何离散化。
光栅化是将几何数据经过一系列变换后最终转换为,从而呈现在显示设备上的过程
光栅化,就是将几何信息转换成一个个的栅格组成的图像的过程。
在光栅化的时候我们已经知道了每个片断(fragment)的深度
现代GPU中运用了Early-z的技术,在Vertex阶段和Fragment阶段之间〈光栅化之后,fragment之前〉进行一次深度测试,如果深度测试失败,就不必进行fragment阶段的计算了,因此在性能上会有很大的提升。但是最终的Z-Test仍然需要进行,以保证最终的遮挡关系结果正确。
图元是由顶点组成的。一个顶点,一条线段,一个三角形或者多边形都可以成为图元。
片元是在图元经过光栅化阶段(这个阶段比较复杂,这里不赘述)后,被分割成一个个像素大小的基本单位。片元其实已经很接近像素了,但是它还不是像素。片元包含了比RGBA更多的信息,比如可能有深度值,法线,纹理坐标等等信息。片元需要在通过一些测试(如深度测试)后才会最终成为像素。可能会有多个片元竞争同一个像素,而这些测试会最终筛选出一个合适的片元,丢弃法线和纹理坐标等不需要的信息后,成为像素。
像素就很好理解了,最终呈现在屏幕上的包含RGBA值的图像最小单元就是像素了。
DTexL: Decoupled Raster Pipeline for Texture Locality
加泰罗尼亚理工大学
Introduction
这篇论文目标是提升LI texture cache的局部性
使用方法:提出了新的工作负载调度器和重新排序线程
shader cores(SCs)执行图形工作负载,SCs中有私有的L1 texture cache
存储器的延迟并不是图形工作负载的主要问题,因为GPU使用多线程来隐藏了存储延迟,性能的提升主要靠带宽
Tile-Based Rendering (TBR) architectures处理的是屏幕的子集:tile
传统的TBR体系结构在一个SC内一次只能处理一个tile,如果工作负载在SC间分布不均匀,这可能会导致SC中的低线程占用期(SC中的线程少),从而降低多线程效率并增加texture cache未命中对核心吞吐量的影响。
如今线程调度器的工作专注于负载均衡,以便为每个区块为SC分配相似数量的线程
但是负载均衡的调度器会导致专用L1 texture cache中的内存块复制,从而降低其聚合容量,局部性较差;专注于texture memory局部性的调度器会导致负载均衡较差。
tile可以按任何顺序处理,每个tile会产生多个线程,这些线程可以按照不同的策略分给不同的SC,因此通过改变tile的处理顺序和给SC的分配顺序能够改变内存访问的局部性
本文通过将线程调度到SC来影响texture memory的访问模式,以支持局部性而不是负载均衡,本文采用两种方法:
- 操纵SC之间的线程分布,从而以最小化缓存块复制并增加纹理缓存的聚合容量的方式操纵专用L1纹理缓存之间的内存访问。即新的线程调度方式
- 控制图形流水线处理tile的顺序,在时间上重新排序内存访问模式。即将内存访问模式重新排序
- 为了将这种改进转化为GPU性能,我们建议对基线(baseline)图形管道进行一次小的修改
总之,本论文做出了以下关键贡献:
- 提出并评估SC的不同工作负载调度器,以改进移动GPU中图形工作负载的纹理缓存
- 结合工作负载调度器提出并评估两个tile顺序,以改进移动GPU中图形工作负载的纹理缓存
- 使用建议的工作负载调度器,L2访问总数减少46.8%
- 对图形流水线进行修改
Background
TBR最初被提出来便利并行着色,tile是帧的不相交的段,能够被并行着色
TBR现在是一种适用于低功耗图形系统的通用架构,tile是在small-tile-sized的片上缓冲区上顺序渲染的,这允许利用局部性并显著减少耗电的DRAM访问并节省内存带宽
TBR和其他的不基于tile的架构相比将外部数据流量的总量减少了1.96倍
Graphics Pipeline
下图是图形流水线的主要阶段
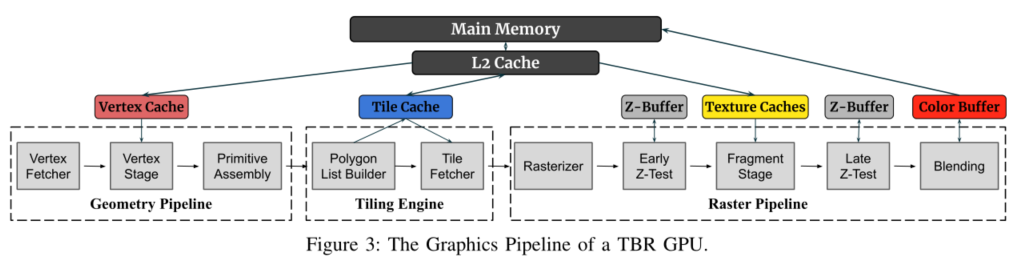
在TBR架构中,raster pipeline被设计为渲染tile而不是整个帧
处理步骤:
- 图形流水线的输入数据是由顶点(vertices)和纹理(textures)组成的。这些顶点连接起来形成不同的多边形(通常是三角形),称之为图元(primitives) ;纹理用于在渲染场景时增强曲面上的细节。
- 一个绘制命令(Draw Command)会触发Geometry Pipeline,然后会从vertex cache中取出顶点,然后根据用户提供的顶点程序将顶点进行变换,primitive assembly以程序顺序获取顶点并将它们连接起来形成图元作为tiling engine的输入,该阶段会由顶点生成图元(如三角形)
- Polygon List Builder的作用是为每个tile生成一个列表,列表中包括了与之有交集的所有图元,列表中保存的是图元的ID。列表以参数缓冲区(Parameter Buffer)的结构排列,参数缓冲区中还保存了图元的属性(颜色、纹理坐标等),每个图元的属性只在参数缓冲区中存储一次(因为节省空间)。参数缓冲区在同一帧中构建并使用
- Tile Fetcher的作用是提取一个tile中的所有图元(利用参数缓冲区),一次提取一个tile的图元(顺序没定),提取的图元放入一个FIFO队列等待Raster Pipeline进行处理
- Rasterizer阶段会从FIFO中取出图元,然后识别当前tile的哪些像素被图元覆盖,然后使用插值法计算像素的属性形成片元(fragment,片元是一组数据,可以看作预备像素,是像素的数据表示),每四个相邻像素的片元被分组形成一个quad发送到Early Z-Test阶段。即光栅化阶段会将图元分割成一个个像素大小的基本单位,片元。再将相邻的片元组合成quad发送出去
- Early Z-Test阶段会存储之前处理过的片元的最小深度到Z-Buffer来消除那些位于另一个先前处理的不透明的片元后面的片元
- Fragment Stage的任务是将通过测试的quad发送到SC,SC会计算quad中每个像素的初始颜色(根据着色器程序),然后将输出颜色发送到blending单元
- 某些渲染技术要求SC更改片元的深度,在这种情况下,Early Z-Test被禁用,而Late Z-Test被使用
- Blending阶段会根据每个quad的透明性来计算quad中每个像素的最终颜色,然后将其保存在Color Buffer中(此时将片元转换为了像素,片元经过测试和混合后成为像素)
- 当一个tile被完全处理完后,color buffer会刷新到frame buffer中
为了提高吞吐量,从Early Z-Test阶段开始,Raster pipeline由几个独立运行的并行流水线实现(为了简单起见,我们将在本文的其余部分假设四条流水线),每个流水线都有自己的SC和专用的L1纹理缓存。Z-Buffer和Color Buffer都被划分为四个bank,因此每个流水线都在缓冲区的不相交部分上操作,以避免访问冲突并提高带宽。
Quad Scheduling
当前GPU专注于线程调度的负载均衡,这对平衡资源利用率非常有效
overdraw是重复绘制同一像素
但是只要重叠的图元不按先后顺序进行渲染就有可能出现overdraw问题;此外,由于几何体并非均匀分布在帧上,某些区域的深度复杂度更丰富的可能会遭受更多的overdraw。因此将许多相邻的quad位置映射到相同处理器会提升那些被高度overdraw的区域被映射到相同处理器的可能性,因此,为了实现分配给每个SC的quad的负载平衡,必须以细粒度的方式将quad调度给SC,以使相邻的屏幕中的相邻quad去往不同的SC
但是由于相邻的quad显示了纹理数据的重用,如果他们去了同一个SC可以避免专用L1cache块的重复。因此,将相邻quad分配给不同的SC会导致专用L1cache中的块复制,并降低可用存储的有效性
Barriers
光栅流水线中会插入barrier来限制每个流水线阶段只处理一个tile,由于以下原因:
- 片上缓存(Z-BUFFER、color buffer)的大小是一个tile的大小,因此使用这些缓冲区的流水线阶段再完成当前tile的处理之前无法移动到下一个tile
- 避免重排序的高开销(Fragment阶段)
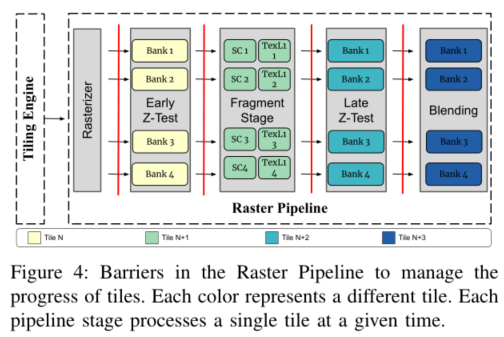
加入barriers后会使得每个流水线阶段只有处理完之前tile中的所有quad后才会被送入新的tile的quad
这些barriers的作用并不是用来作线程同步的,是为了确保光栅流水线中每个阶段一次只处理一个tile
Memory Organization
下图左侧是存储层次结构,右图是图形应用程序使用的主要数据结构(存储在左侧的结构中),可以看出有多个指令和数据的L1 Cache
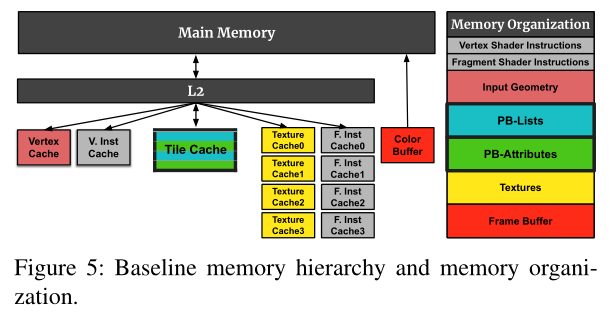
DTexL
本文的主要贡献:
- 通过控制对SC集合的内存访问流的调度方式来实现支持在quad调度期间支持texture局部性并仍然保持负载均衡,提高私有L1 texture cache的缓存功能
- 调整光栅流水线以对抗随后的负载不均衡,并实现gpu性能和能耗的显著改善
主要挑战:
- 根据将tile划分成四个子tile的映射,quad被调度到四个SC中。如果overdraw的quad没有在子tile之间均匀分布会导致负载不均衡,克服这种不平衡的最简单方法是使用细粒度映射,将空间上相邻的quad分配给不同的SC
- 在屏幕中相邻的quads很有可能具有空间局部性,因为他们的纹理像素可能被映射到相同的缓存块;同时还可能具有时间局部性,取决于纹理化过程中使用的滤波类。因此对相邻quad的分组会导致L1 texture cache的缓存性能更好(即子tile的分割问题)
- 相邻tile之间会共享边,存在隐藏的局部性。因此,确保来自连续tile的相邻子tile进入同一SC将增强纹理局部性
- 专注于纹理局部性的quad调度器倾向于将粗粒度区域映射到相同的SC(相邻的quad成组),这会导致显著的负载不均衡,导致与旨在负载均衡的细粒度调度器相比,GPU的总性能相等或更差
Our Approach
提出了新的tile顺序,在最大化纹理存储器的局部性
最大化纹理存储器的局部性会导致负载不均衡,因此提出了解耦光栅流水线来克服由此产生的负载不均衡
Quad Mapping
图元经过光栅化阶段后会生成片元,然后将相邻的四个片元组成一个quad,这些quads会被映射到Z-Buffer中四个bank,因此要对quad进行分组(这些quad都属于同一个tile)
我们将映射到同一个bank的quads称为一个subtile,然后这些subtiles就会被分配到四个SC中的一个进行处理
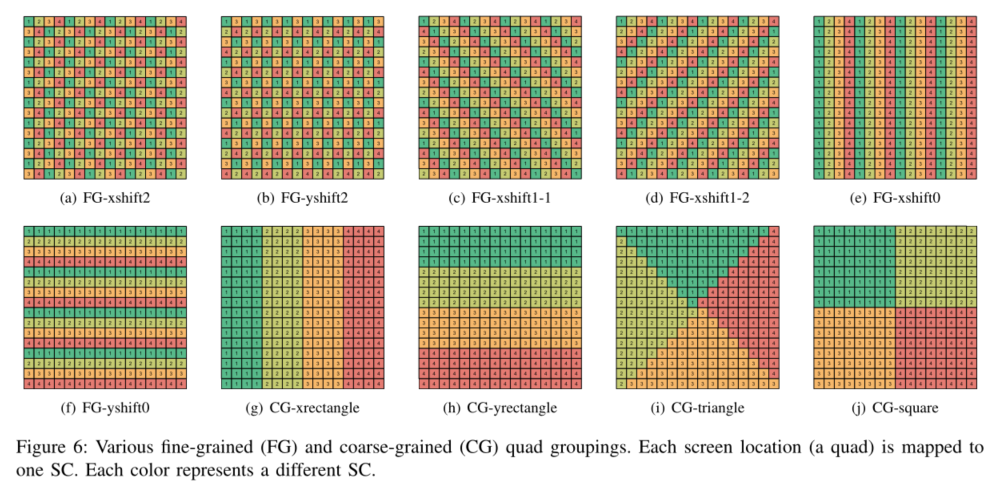
Quad Grouping
由于overdrawn图元会集中在特定区域中,一个tile中可能有更多quad集中在该区域,为了负载均衡,下图中的a-f给出了细粒度的分组方式。a和b确保了没有相邻的quad进入同一个SC中;c和d中每个quad允许最多2个对角相邻quad进入同一SC;e和f分别允许最多两个竖直的和两个水平的相邻quad进入同一个SC
图g-j是为了减少L1纹理cache中块的复制和保进行的分组
Subtile Assignment
subtile之间会有共享边,而又因为tile处理顺序的不同,不同tile之间也会有共享边,每个tile与上一个处理的tile之间最少共享了一条边,这些共享边之间会存在隐藏的局部性
将同一tile内相邻的subtile分给同一个SC和将不同tile之间相邻的subtile分配给同一个SC可能会提升局部性
不同tile之间相邻subtile与tile处理的顺序有关
Tile Orders
图形中最著名的扫描线顺序和Z顺序,扫描线顺序是一行一行处理tile,而Z顺序如下图左边所示,右图是Hilbert顺序,在数值分析中更出名
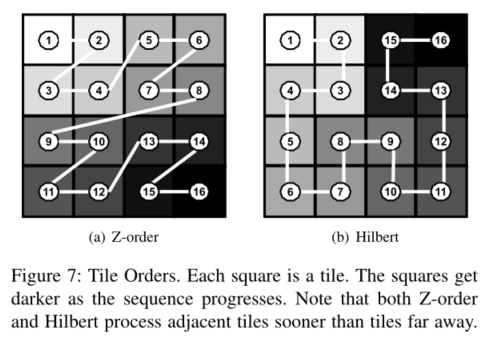
Hilbert顺序只在特定工作负载中表现比Z顺序更好
Hilbert主要是因为计算ID更复杂,但是在TBR架构中的tile数量不多,可以预先计算避免此类开销;而且Hilbert顺序并不适用于矩形,但是移动屏幕主要是矩形
本文提出了一种适用于矩形区域的Hilbert顺序,我们将希尔伯特阶应用于具有8X8 tiles的正方形子帧,然后将帧中的所有子帧以波状遍历,换句话说,以S形遍历。
Tile Order and Subtile Assignment
下图中的帧是由16个tile组成的,展示了8中tile顺序
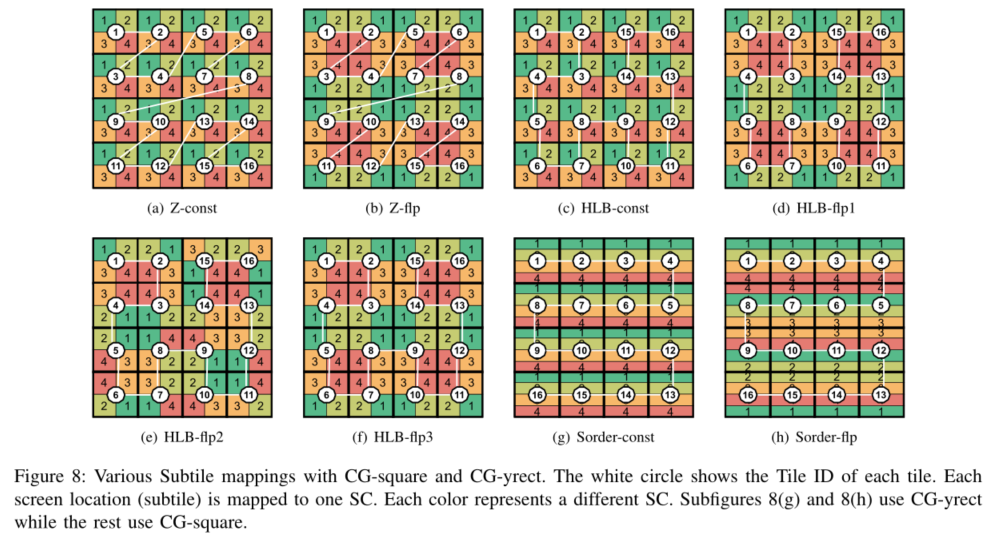
a,c,g的顺序中,不同tile的subtile不共享边,而其他五种顺序是共享边的
d中在顺序处理中只是沿着共享边对称翻转
b中的1从不共享边,而4倾向于始终共享边,e和h克服了这种不平衡,当从偶数tile到奇数tile时,会沿着共享边翻转的同时也会反转非共享subtile
在f中,我们每16个tile翻转所有四个subtile,这样相同的FP每次都不会处于优势或劣势
总结:
- 将所有tile中对应位置的subtile都映射到同一个SC不能充分探索局部性
- 在tile执行顺序中每次只沿着共享边翻转subtile的分布能够利用局部性,但是会导致一个subtile始终具有共享边的优势
- e,f,h克服了不平衡,在整个帧过程中为所有SC提供了公平的共享边份额

