
Cache Replacement Policies
- 注:驱逐(evict)和替换(replacement)在这是一个意思
Introduction
提高cache命中率的方法
- 增大cache的大小,但是会增加延迟
- 提升cache的相联度,可以减少冲突带来的缺失,但是会增加功耗和硬件复杂性
- 改善cache的替换策略
A Taxonomy of Cache Replacement Policies
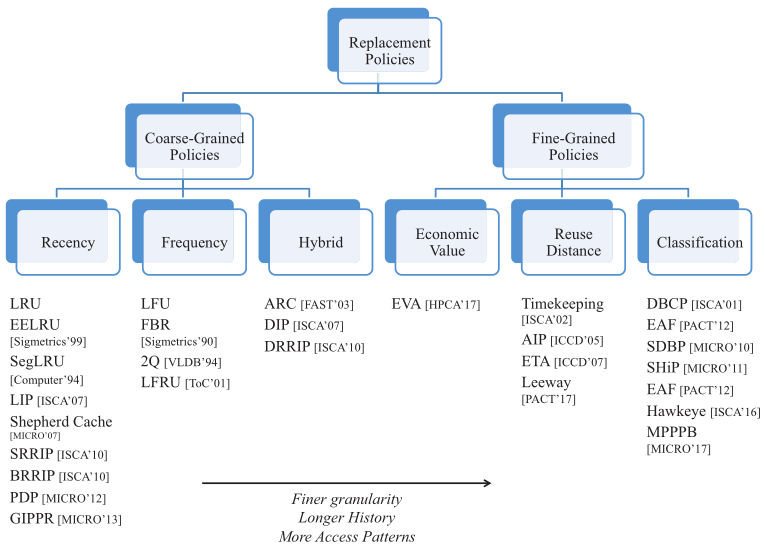
首先根据插入cache line时的粒度将策略分为粗粒度和细粒度:
- 粗粒度算法在cache line插入时平等对待所有的line,只根据插入之后的行为来区分它们。粗粒度算法又根据基于他们用来区分缓存驻留行(cache-resident line)的度量分为以下三类:
- 根据访问的新近程度(recency)进行排序,使用一个概念上的recency stack
- 根据访问的频率进行排序,使用一个频率计数器
- 混合策略,会动态选择最好的粗粒度算法
- 细粒度算法在cache line插入时就有优先级之分,他们通过使用来自缓存行的组(group)之前生命周期的信息来做出这些区分。根据区分的度量分为两类
- 基于分类的策略:分为cache-friendly(高优先级)和cache-averse(低优先级),然后在cache-friendly的cache line中又会根据其他策略(比如recency)进行排序
- 基于重用距离(reuse distance)的策略,超出预期重用距离但未收到命中的行将从缓存中逐出
Coarse-Grained Replacement Policies
RECENCY-BASED POLICIES
下面的策略是基于时间新进程度来进行处理的,都维护一个recency stack
LRU
LRU算法会将新插入的cache line放入MRU位置,每次命中就会将其重新放置MRU位置,如果没有命中,则向LRU的位置靠近,每次替换时选择LRU位置的cache行进行替换

但是当工作集大于cache的大小时会出现抖动的问题,比如下面的例子
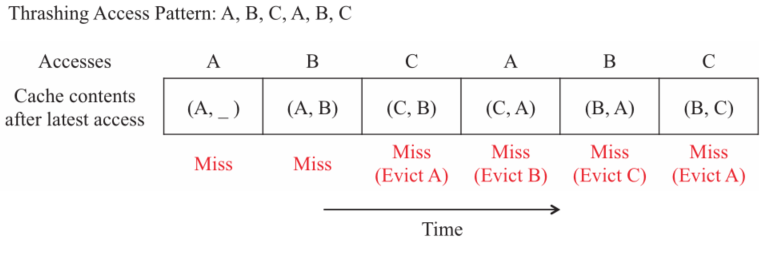
同时在有扫描访问的情况下表现很差,因为其会替换掉一些可能重复使用的旧cache行来缓存最近使用的扫描行,而扫描行只会使用一次
MRU
Most Recently Used(MRU)是LRU的变体,主要是为了缓解抖动的问题。其会替换最近使用的cache行,保存最远使用的cache line。如果使用LRU的例子,可以减少一次MISS,A会重新命中一次
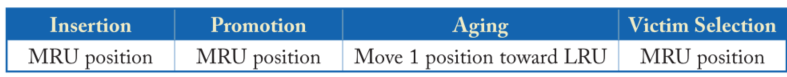
LIP
The LRU insertion policy (LIP) 是结合了LRU和MRU,插入算法是LRU,但是替换算法使用MRU
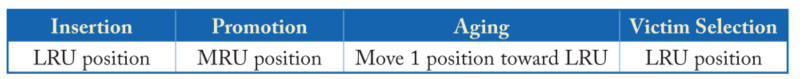
EELRU
Early Eviction LRU(EELRU)的主要思想是检测工作集的大小是否超过了cache的大小,如果超过了cache的大小则提前替换一些cache行
其将cache行分为了三个部分:lru memory\early region\late region。如下图所示
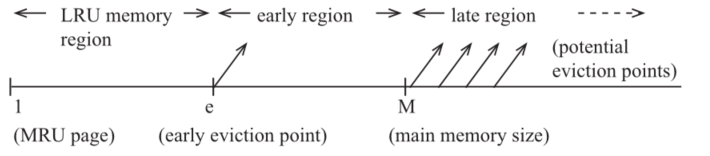
当三个区域的命中数的分布呈单调递减,则说明工作集的大小适配cache的大小,没有抖动发生,此时会替换lru行;如果late region的命中数超过了early region,则会替换掉第e个最近使用的cache行

Seg-LRU
Segmented LRU (Seg-LRU)主要是对扫描访问类型进行了优化,更倾向于保留那些使用两次以上的cache行
seg-lru将lru stack分为两个逻辑段,第一个是试用段,另一个是保护段。新的cache行会插入试用段,当其再被命中时会被提升到保护段,当保护段满了时会选择其最远使用的cache行换入试用段,因此保护段中的cache行至少被访问过两次(一次换入,一次命中),这样可以避免扫描行换入保护段。替换时选择试用段中的最远使用的行进行替换。
其替换算法如下面两张图所示
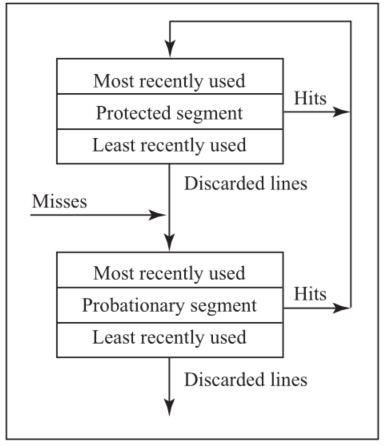

BIP
抵抗抖动的策略(如MRU,LIP)并不能适应工作集变化
Bimodal Insertion Policy (BIP)算法在cache行插入时有较低的几率插入到MRU位置,其余时候都插入到LRU位置,这样在大部分时间都能够抵抗抖动,偶尔也通过保留较新的行来适应工作集阶段性的变化

SRRIP
Static Re-Reference Interval Prediction (SRRIP)提出的观点是缓存替换可以被认为是一个再引用间隔预测(Re-Reference Interval Prediction ,RRIP)问题,而传统的LRU链可以被认为是一个RRIP链
位于RRIP链头部的行被预测为最快被重新引用(最短的重新引用间隔),而位于RRIP链尾部的行被预测为在未来最远被重新使用(最长的重新引用间隔)
通过这种观点,LRU策略预测新插入的行有最短的重新引用间隔(插入RRIP链的头部),LIP策略预测新插入的行具有最长的重新引用间隔(插入RRIP链的尾部),如下图所示,这个RRIP链用一个2比特的再参考预测值(RRPV)来表示: 00对应的是最近的再参考区间预测,11对应的是远的再参考区间预测。
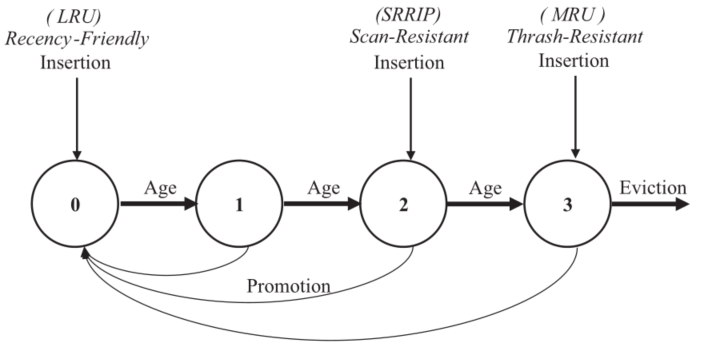
SSRIP将新插入的行插入RRIP链的中间,这样可以使替换策略适应不同访问模式,可以抵抗扫描行。如果命中,才会提升到头部,在缓存缺失时,RRIP链尾部的行被替换

BRRIP
SRRIP仍然存在抖动的问题
Bimodal re-reference interval prediction policy (BRRIP)更改了SRRIP的插入策略,大多数时间都插入在PPRV=3的地方(LRU位置),有一定几率插入RRPV=2的位置。思想和BIP类似

PDP
Protecting Distance-Based Policy (PDP)动态地估计了一个保护距离(protecting distance,PD),所有的缓存行在被驱逐之前都被保护在PD访问中。PD是一个单一的值,用在插入到cache中的所有行,但它会根据应用程序的动态行为持续更新
为了估计PD,PDP计算重用距离分布(RDD),这是在程序执行的最近间隔内观察到的重用距离分布。使用RDD,PD被定义为覆盖cache中大多数行的重用距离,这样大多数行都在PD或更小的距离上被重用
在插入或提升时,每个cache行被分配一个值来代表它的剩余PD(remaining protecting distance,RPD),这是它保持保护的访问次数;这个值被初始化为PD。在每次访问一个集合后,该集合中每一行的RPD通过递减RPD值而老化(饱和为0)。只有当一个cache行的RPD大于0时,它才是受保护的
一个未受保护的行会被替换
GIPPR
Genetic Insertion and Promotion for PseudoLRU Replacement (GIPPR)引入了插入/推广向量(Insertion/Promotion Vector,IPV)的概念。
对于一个k-way set-associative cache,IPV是一个k+1-entry的整数向量,整数范围从0到k -1。其中第i($0 <= i <= k-1$)个位置的值代表第i个位置的行在命中时应该被提升到的新位置。IPV中的第k个条目代表一个新进来的块应该被插入的位置。具体的例子见下图,第一个代表LRU,第二个代表一个更复杂的插入和推广策略
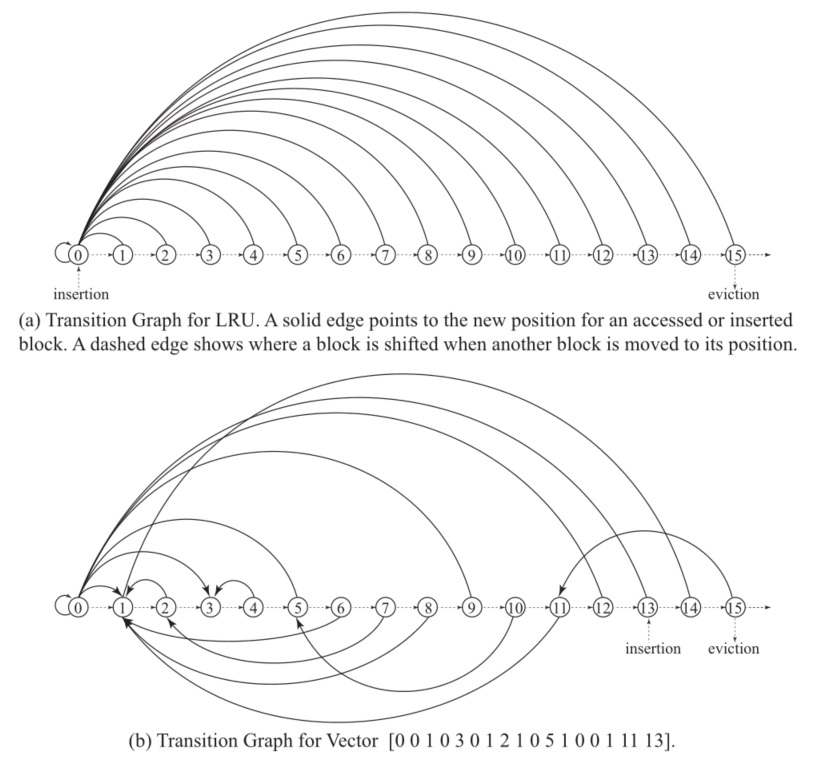
当发生位置变化时,原来的cache行自动进行后移。可通过离线的genetic search得到特定BENCHMARK下的IPV
Shepherd Cache
Shepherd Cache将cache分为main和shepherd两部分,MC使用LRU,SC使用FIFO替换策略
新的cache行首先放入SC中,在此期间统计MC中的访问状况。若这个cache行在离开SC时,MC中存在没有被访问的单元,则进行SC->MC的替换。但该方法的问题是lookahead来源于SC,但SC过大则会导致MC容量不足
FREQUENCY-BASED POLICIES
基于频率的政策使用访问频率来识别替换者,这种方法不容易受到扫描的干扰,其好处是可以考虑到较长时期内的重复使用行为,而不是仅仅考虑最后一次使用
LFU
Least frequently used (LFU)策略是最简单的基于频率的策略,使用一个频率计数器,插入的行初始化为0,每次访问会加一,替换计数器最小的行

LFU面对应用程序阶段性的变化适应性很差,因为上一阶段使用频率很高的cache行,即使在下一阶段几乎不使用,其仍然保存在cache中
FBR
Frequency-Based Replacement (FBR)将cache行划分为三个部分:new/middle/old。其同时维护一个recency stack和计数器
当new部分的cache行命中时不会增加计数器,只会将其移至MRU位置;middle、old部分的行在命中时会增加计数器的值,同时将其移至MRU位置;替换时会选择old部分的行的LFU进行替换

LRFU
Least Recently/Frequently Used (LRFU)使用一种新的指标:Combined Recency and Frequency (CRF)。其结合了recency和frequency的信息,为每个cache行都计算了CRF值。替换时会选择最小的CRF值的cache行进行替换
下面是cache行b的LRFU替换策略

- 权重函数:$F(x)=({\frac{1}{p}})^{\lambda x}$,其中$\lambda$是经验参数
HYBRID POLICIES
混合策略评估应用程序当前工作集的要求,并从多个竞争性策略中动态选择
其面临的两个挑战:
- 准确选择更合适的策略
- 以较小的开销管理多个策略
ARC
The Adaptive Replacement Cache (ARC)跟踪了两个额外的tag目录:
- L1保持最近使用过的而且只出现过一次的行,基于Recency
- L2保持最近访问过的而且已经至少出现过两次的行,基于Frequency
ARC的目标是动态选择合适的cache行来贡献给L1和L2,即动态调整L1和L2的大小
具体来讲,ARC将cache 目录分成两个列表T1和T2,分别保持最近使用过的而且只出现过一次的行和最近访问过的而且已经至少出现过两次的行。然后从T1和T2扩展出幽灵列表B1和B2,用于跟踪从T1、T2中替换出的行。T1和B1共同组成L1,T2和B2共同组成L2
B1和B2只保存元数据(tag这些),不保存真正的数据
ARC动态地调节专用于T1和T2的缓存空间。一般来说,B1的命中会增加T1的大小(专门用于最近访问的元素的缓存比例),而B2的命中会增加T2的大小(专门用于至少两次访问的元素的缓存比例)
其缺点是要维护额外的tag目录开销
DIP
Dynamic Insertion Policy (DIP)在LRU和BIP进行动态选择,其使用Set Dueling计数来动态跟踪两种策略的命中率
其方法示意如下图所示,DIP将一些sets用于LRU(图中的0、5、10和15),将一些sets用于BIP(图中的3、6、9和12),这些被分配的sets称为set dueling monitors (SDMs)
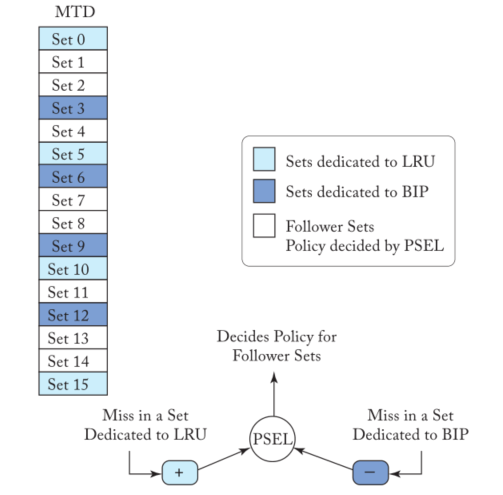
PSEL是个饱和计数器,当专门用于LRU的SDM收到一个命中时,PSEL被递增,而当专门用于BIP的SDM收到一个命中时,它被递减;当PSEL的最高位为1时,follower sets使用LRU策略,否则使用BIP策略
DRRIP
Dynamic Re-Reference Interval Policy (DRRIP)在DIP的基础上进一步添加scan-resistance。动态使用SRRIP(比LRU添加了scan-resistant, 新插入的Re-Reference Interval Prediction在中间)和BRRIP(新插入的RRIP为2或3,可抵抗scan和thrashing情况)
Fine-Grained Replacement Policies
细粒度的策略在插入时区分cache行,通常基于cache行先前生命周期的替换信息来区分。通过学习先前cache行的行为,细粒度策略可以更有效地使用cache
细粒度策略基于预测插入优先级的指标分为三大类:
- 预测重用距离(reuse intervals)
- 预测二进制缓存决策(binary caching decision)?
- 引入新预测指标
还有其他几个设计维度:
- 学习cache行组的缓存行为,而不是一个cache行
- 学习缓存行为的历史量
细粒度替换策略的背景:
- 使用预测来识别dead block,其可以用作预取缓冲区
- 关闭失效的cache行
REUSE DISTANCE PREDICTION POLICIES
EXPIRATION-BASED DEAD BLOCK PREDICTORS
许多dead block预测器使用过去的驱逐(evict)信息来估计平均重用距离,驱逐在其预期重用距离内未重用的行,下面是定义重用距离的几种方法:
- 使用cache行的生存时间(live time),生存时间定义为行在cache中保持活跃的周期数。当一个cache行被插入时,其生存时间设置为上次在cache中的生存时间。如果该行在cache中停留了其生存时间的两倍而没有收到命中,则该行被声明为dead且被驱逐
- 使用连续引用之间的缓存访问次数来定义一个cache行的重用距离
- 使用计数器来跟踪每个cache行的访问间隔,其中一行的访问间隔被定义为在对该行的后续访问之间访问的其他cache行的数量。如果一行的访问间隔超过某个阈值,他们会预测该行dead。阈值由访问间隔预测器 (AIP) 预测,它跟踪所有过去驱逐行的访问间隔,并在基于 PC 的表中记住所有此类间隔的最大值
- 使用生存距离(live distance):cache行中观察到的最大堆栈距离来识别dead block。一个cache行的生存距离是从该行的前几代中学习的,当一行超过它的生存距离时,它被预测为死亡。
REUSE DISTANCE ORDERING
该方法驱逐预计在未来被重用最远的行
主要是为每个load指令的PC学习一个重用距离,为每个插入的行计算一个预估访问时间(estimated time of access,ETA);然后基于ETA对cache行进行排序,驱逐具有最大ETA的行
- ETA定义为当前时间和预期重用距离的和
为了防止ETA预测不可控,这个方案还跟踪了行的衰减(decay)间隔:cache行在cache中保持未被访问状态的时间的估计。其会驱逐掉衰减间隔大于ETA的cache行
CLASSIFICATION-BASED POLICIES
基于分类的策略的优势:
- 与混合策略相比(在一个给定的时间段内给所有行一个统一的决策),基于分类的策略可以插入一些高优先级的行和一些低优先级的行
- 基于重用距离的策略的目标是预测一个重用距离,这是个数字,有多个值;而基于分类的策略是一个二元预测问题,只预测两个值
基于分类的策略都有两个特点:
- 它们都包括一个二进制预测器,学习cache过去的行为来指导未来的行为
- 都借用的最先进的粗粒度策略中的promote、aging和evict方案,这有助于它们考虑到不准确的预测
SAMPLING BASED DEAD BLOCK PREDICTION (SDBP)
主要想法是预测死块(dead block):一个在被驱逐之前不会再被访问的cache块
预测的思想:
- 如果一个指令地址的踪迹导致了一个块的替换,那么下次相同的踪迹也会导致一个块的替换
- 使用pc来进行训练
具体方法:
- 当cache miss时访问预测器,如果对应pc预测为取出死块,则对取出的cache块进行标记,下次替换时优先替换
SDBP通过一个解耦的采样器来进行学习与训练,该采样器使用一小部分缓存访问来填充,如下图所示。当一个块在sampler中没有重新使用而被驱逐,预测器中相应的pc就会负向训练,否则进行正向训练。采样器只采样一小部分L2 miss。采样器中的相联度和替换策略不一定要求和cache中的一致
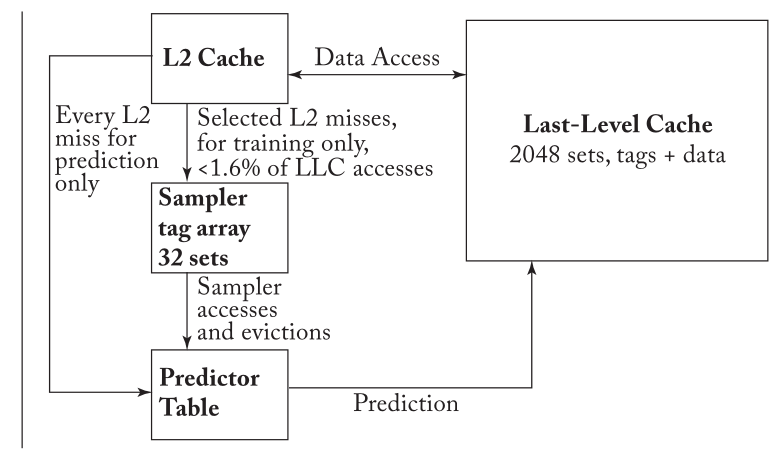
SDBP的替换算法如下,只对没有标记为dead的块使用LRU算法进行管理

SDBP绕过所有被预测为cache-averse的块,其余的块使用基线替换策略进行管理,因此假阳性(被预测为cache-friendly的cache-averse的块)使用基线替换策略进行老化,而假阴性没有任何机会被重复使用
SIGNATURE BASED HIT PREDICTION (SHIP)
cache行是否活跃与“插入它”的PC关联更大,而SDBP只学习了最后一次访问它的PC
因此,在缓存驱逐时,SHIP的预测器是以在缓存缺失时第一次插入该行的PC来训练的,并且预测器只在缓存缺失时被查询(在命中时,行被提升到最高优先级而不咨询预测器)
SHIP是基于RRIP策略来进行管理的,如下图所示

SHIP只采样训练一部分的cache行,称为采样集,其余的cache行用签名与采样集相关联。在采样集中的缓存命中时,与该行关联的签名被正向训练,并且在逐出从未被重用的行时,签名被负向训练。当插入新行时,传入行的签名用于咨询预测器并确定传入行的重新参考间隔(对所有访问执行预测,而不仅仅是采样集)
它通过将每个引用与唯一签名相关联,将传入的行分类到不同的组中

