
FDIP设计总结
主要思想:
- 取指导向的预取;
- 使用FTQ将分支预测部分和取指令部分解耦;
- 使用icache中闲置的端口来进行重复预取的探测过滤,减少总线事务;
- 尽量预取那些容易确实的set中的cache line。
下面是其架构:
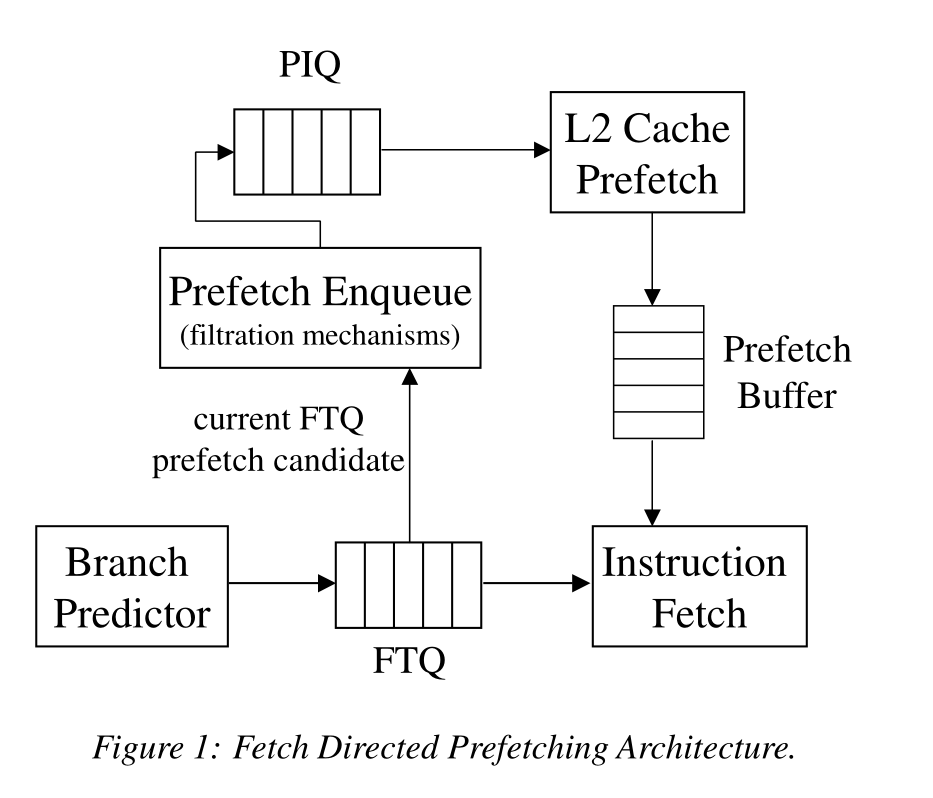
预取步骤:
- 分支预测器预测目标地址,如果FTQ满了就停止预测,否则就在FTQ中插入一项或多项(取决于预测器能一次预测几个地址);
- 在icache中的每个set中都使用了一个饱和计数器来指示该set是否为频繁miss的set,FTQ中只有目标地址位于频繁miss的set中时才会被标记为候选预取项,候选位置1,节省总线带宽。
- 预取引擎会在FTQ的第2-10项中的候选项中选择预取项(实验所得最佳候选顺序)插入PIQ中排队进行预取,同时也会给其在prefetch buffer中分配对应条目。如果prefetch buffer已满则不再预取;
- icache和prefetch buffer(全相联FIFO)进行并行查找,如果在prefetch buffer中找到,则将其删除,然后插入到icache中。
- 同时会使用icache中闲置的取指端口来探测过滤icache,节省总线带宽,有两种方式:
- enqueue CPF:每次都会使用闲置端口来探测icache中的所有块,只预取不存在于icache中的候选目标地址。
- remove CPF:默认将所有候选目标地址放入PIQ中,每当icache有闲置端口可用时就进行探测,取消预取icache中已存在的块,删除PIQ和prefetch buffer中对应项
注意:
- FTQ项是由一个候选位,一个有效位,一个入队位和分支目标地址构成。候选位表示该缓存块是被预取的候选块,入队位表示已经插入了PIQ中进行预取;
- 当分支预测错误时会刷新所有的缓冲区和队列,因此分支预测器的准确性极大的影响了预取的效果。
FDIP会占用大量的总线带宽,但是平均可实现 25% 至 40% 的最高加速,为了进一步减少总线带宽,向icache的标签阵列添加额外的端口以提供额外的探测过滤可能是有益的。

